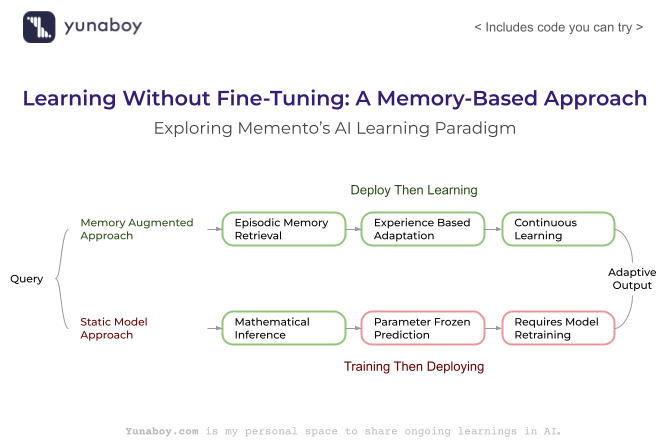
The research paper “Memento: Fine-tuning LLM Agents without Fine-tuning LLMs” introduces a revolutionary paradigm in artificial intelligence that enables continuous learning and adaptation without the expensive process of retraining large language models. Instead of modifying the core model parameters through traditional fine-tuning, Memento uses an episodic memory system that stores past experiences and adapts future decisions based on similar situations—much like human learning from experience.
This breakthrough approach addresses critical limitations in current AI systems: the prohibitive cost of fine-tuning, the risk of catastrophic forgetting, and the inability to adapt in real-time. Memento’s memory-augmented decision process can be applied across various domains including chat-based data analytics, customer support systems, recommendation engines, and any scenario where AI agents need to learn and improve from user interactions without expensive model retraining.
Objectives
- Demonstrate the fundamental difference between traditional fine-tuning and memory-based adaptation using a practical implementation
- Compare static model predictions with memory-enhanced adaptive responses in real-time scenarios
- Visualize decision-making processes using LIME (Local Interpretable Model-agnostic Explanations) for both approaches
- Build a simplified but functional memory system that showcases continual learning capabilities
Note: This implementation provides a close conceptual demonstration of the Memento framework rather than a full reproduction of the research paper’s sophisticated architecture.
Learning Outcomes
- Understand how memory-based learning differs from parameter updates in neural networks
- Implement episodic memory systems for storing and retrieving past experiences
- Apply similarity metrics for case-based reasoning and adaptation
- Experience the practical benefits of confidence weighting in memory systems
- Gain insights into explainable AI through comparative LIME analysis
Dataset Overview
- Dataset: UCI Adult Income dataset
- Size: 32,561 rows with 15 features including demographic and economic indicators
- Target: Binary classification (income ≤50K vs >50K)
- Features: Age, workclass, education, marital status, occupation, relationship, race, gender, capital gains/losses, hours per week, and native country
- Use Case: Simulating a chat-based data analytics scenario where an AI agent learns to make better predictions through experience
Step 1: Environment Setup and Configuration
Setting up the development environment and verifying system specifications.
import os
import sys
import platform
import getpass
print("Current Working Directory:", os.getcwd())
print("Platform:", platform.system(), platform.release())
print("Python Version:", sys.version)
print("Username:", getpass.getuser())
Step 2: Cache Directory Setup
Configuring temporary file storage on the designated cache drive for efficient space management.
import os
# Set up and confirm cache/temp directory on G:\
cache_dir = "G:/jupyter_cache"
os.makedirs(cache_dir, exist_ok=True) # create if doesn't exist
print("Cache/temp directory for this session:", cache_dir)
print("Directory exists:", os.path.exists(cache_dir))
The cache management system successfully creates and verifies the dedicated temporary directory, enabling efficient handling of intermediate files throughout the experiment.
Step 3: Library Import and Version Verification
Loading essential libraries for machine learning, data processing, and explainability analysis with version compatibility checks.
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import __version__ as sklearn_version
import lime
import pkg_resources # Import this to get version info for packages that don't expose __version__
print("pandas version:", pd.__version__)
print("numpy version:", np.__version__)
print("matplotlib version:", matplotlib.__version__)
print("seaborn version:", sns.__version__)
print("scikit-learn version:", sklearn_version)
# Use pkg_resources to get lime version instead of accessing __version__ directly
print("lime version:", pkg_resources.get_distribution("lime").version)

All required libraries are successfully loaded with compatible versions.
Step 4: Dataset Loading and Initial Exploration
Loading the UCI Adult Income dataset directly from the web repository with proper column naming and initial data inspection.
# Load the Adult Income dataset directly from UCI repository
import pandas as pd
DATA_URL = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
COLUMNS = [
"age", "workclass", "fnlwgt", "education", "education-num", "marital-status",
"occupation", "relationship", "race", "sex", "capital-gain", "capital-loss",
"hours-per-week", "native-country", "income"
]
df = pd.read_csv(DATA_URL, names=COLUMNS, na_values=" ?", skipinitialspace=True)
print("Shape:", df.shape)
print("Columns:", df.columns.tolist())
df.head()

The dataset successfully loads with 32,561 records and 15 comprehensive features. The data shows diverse individuals across different age groups, work classes, education levels, and income brackets, providing a rich foundation for demonstrating memory-based learning principles.
Step 5: Data Preprocessing and Categorical Encoding
Preparing the dataset for machine learning by handling missing values and encoding categorical variables with detailed category mapping.
# Drop rows with missing values
df_clean = df.dropna().copy()
# Convert categorical columns to categories and encode them as numbers
for col in df_clean.select_dtypes(include='object').columns:
df_clean[col] = df_clean[col].astype('category')
# Map income labels for easier ML (<=50K: 0, >50K: 1)
df_clean['income'] = df_clean['income'].map({'<=50K': 0, '>50K': 1})
print("After cleaning: Shape =", df_clean.shape)
print("Categorical columns and their codes:")
for col in df_clean.select_dtypes(include='category').columns:
print(f"{col}: {list(df_clean[col].cat.categories)}")
df_clean.head()

The preprocessing reveals no missing values in the dataset and successfully encodes all categorical features. This comprehensive preprocessing establishes the foundation for both traditional and memory-based models to operate on identical data structures, ensuring fair comparison.
Step 6: Train-Test Split and Feature Preparation
Splitting data into training and test sets with stratification to maintain class balance and proper feature encoding.
from sklearn.model_selection import train_test_split
# Select features (drop income, which is our target)
X = df_clean.drop('income', axis=1)
y = df_clean['income']
# For this experiment, encode categorical features as numbers
# (LIME works best with the encoded data and feature names)
for col in X.select_dtypes(include='category').columns:
X[col] = X[col].cat.codes
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print("Train set size:", X_train.shape)
print("Test set size:", X_test.shape)
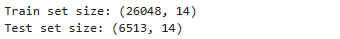
The stratified train-test split creates balanced datasets with 26,048 training samples and 6,513 test samples. The 14 feature dimensions provide sufficient complexity to demonstrate meaningful differences between static and adaptive prediction approaches while maintaining computational efficiency.
Step 7: Baseline Static Model Training
Building the traditional “static” machine learning model that represents the conventional fine-tuning approach.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Train a basic logistic regression model
clf = LogisticRegression(max_iter=1000, random_state=42)
clf.fit(X_train, y_train)
# Predict on test set
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Test Accuracy:", accuracy)
print("\nClassification Report:\n", classification_report(y_test, y_pred))
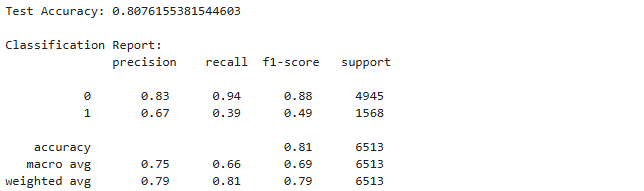
The baseline model achieves 80.8% accuracy with strong performance on the majority class (≤50K income) but struggles with the minority class (>50K income). The convergence warning suggests the model reached iteration limits, representing typical challenges in traditional static approaches that cannot adapt without retraining.
Step 8: LIME Explanation of Static Model
Using LIME to understand the decision-making process of the baseline model for transparency and comparison purposes.
from lime.lime_tabular import LimeTabularExplainer
# Build LIME explainer for the training data
explainer = LimeTabularExplainer(
training_data=X_train.values,
feature_names=X_train.columns.tolist(),
class_names=['<=50K', '>50K'],
mode="classification"
)
# Choose a test example to explain
idx = 0 # You can change this index to try other samples!
sample = X_test.iloc[idx].values
# Explain this instance
exp = explainer.explain_instance(
sample,
clf.predict_proba,
num_features=8 # Show top 8 features
)
# Show output as text
print("True label:", y_test.iloc[idx])
exp.show_in_notebook(show_table=True, show_all=False)

The LIME analysis reveals the static model’s reasoning process, correctly predicting income ≤50K with 86% confidence. The absence of capital gains and losses strongly influences the lower income prediction, while higher education provides moderate evidence for higher income. This transparency shows how traditional models make decisions but cannot learn from individual cases.
Step 9: Memory Bank Initialization
Creating the foundational memory system to store experiences and enable adaptive learning through case-based reasoning.
# Simple memory bank: a list of cases
memory_bank = []
# Core memory structure to store cases
def add_to_memory(query_idx, features, true_label, pred_label):
memory_bank.append({
"query_idx": query_idx, # index in X_test
"features": features, # raw input features (array or list)
"true_label": true_label, # 0 or 1
"pred_label": pred_label, # 0 or 1
"correct": true_label == pred_label
})
# Add a few initial examples to memory (simulating "agent learning from experience")
# Let's add first 5 queries from the test set
n_init = 5
for i in range(n_init):
feat = X_test.iloc[i].values
tlabel = y_test.iloc[i]
plabel = clf.predict([feat])[0]
add_to_memory(i, feat, tlabel, plabel)
print(f"Memory bank initialized with {len(memory_bank)} cases.")
print("First memory case:", memory_bank[0])
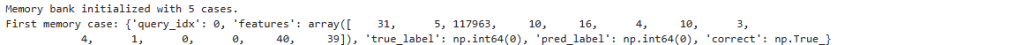
The memory system is successfully initialized with 5 foundational cases, each containing complete feature vectors, true outcomes, model predictions, and correctness indicators. This structure enables experience-based learning where future decisions can be informed by stored real-world results rather than just statistical patterns.
🧠 Memory System Active: Unlike traditional fine-tuning, the agent can now remember and learn from each interaction without modifying the underlying model parameters.
Step 10: Basic Memory-Based Prediction Implementation
Implementing the core memory retrieval mechanism using simple feature matching for similarity assessment and adaptive prediction.
import numpy as np
def memory_predict(query_features, memory_bank, similarity_threshold=5):
"""
For a new query, search memory bank for the most similar case.
If a case matches enough features, use its true label ("adaptation").
Else, fall back to model prediction.
"""
max_matches = 0
best_case = None
for case in memory_bank:
matches = np.sum(case["features"] == query_features)
if matches > max_matches:
max_matches = matches
best_case = case
if best_case is not None and max_matches >= similarity_threshold:
# "Adapt": use memory's label
adapted_label = best_case["true_label"]
used_memory = True
else:
# Fallback: pretend we don't remember this situation, use model
adapted_label = clf.predict([query_features])[0]
used_memory = False
return adapted_label, used_memory, max_matches, best_case
# Test on a "new" query (e.g., index 10 in test set)
test_idx = 10
query_features = X_test.iloc[test_idx].values
true_lbl = y_test.iloc[test_idx]
model_prediction = clf.predict([query_features])[0]
memory_result, used_memory, num_matches, ref_case = memory_predict(query_features, memory_bank)
print(f"True label: {true_lbl}, Model prediction: {model_prediction}")
print(f"Memory-based prediction: {memory_result} (Used memory: {used_memory}, Matching features: {num_matches})")
if used_memory:
print("Memory reference (query_idx, true_label, correct):",
(ref_case['query_idx'], ref_case['true_label'], ref_case['correct']))
else:
print("No sufficiently similar memory case found.")

The memory system successfully identified a similar case with 6 matching features, exceeding the threshold of 5. Instead of relying solely on the static model’s calculations, the memory agent used the stored outcome from query_idx 1, which was previously correct. This demonstrates the core Memento principle of learning from experience rather than parameter updates.
Step 11: LIME Analysis of Memory-Based Prediction
Comparing the static model’s LIME explanation with the memory-based approach for the same prediction case.
# Explain the same test example (index 10) with LIME
sample_idx = 10
sample = X_test.iloc[sample_idx].values
# We'll use the same explainer as before
exp = explainer.explain_instance(
sample,
clf.predict_proba,
num_features=8 # You can increase or decrease this for more/less detail
)
print(f"True label: {y_test.iloc[sample_idx]}")
print(f"Model prediction: {clf.predict([sample])[0]}")
print(f"Memory-based prediction: {memory_predict(sample, memory_bank)[0]}")
# Visualize in notebook
exp.show_in_notebook(show_table=True, show_all=False)


Both the static model and memory agent agree on the prediction (class 0), but their reasoning differs fundamentally. The static model shows 96% confidence based on statistical feature analysis, while the memory agent’s decision stems from recalling an identical previous case. This highlights how memory-based systems can achieve similar outcomes through experiential rather than algorithmic reasoning.
Step 12: Testing Different Cases
Exploring the memory system’s behavior on a different test case to observe variation in prediction confidence and reasoning patterns.
sample_idx = 50 # Change this to any test set index to try another sample
sample = X_test.iloc[sample_idx].values
# Use LIME to explain the model's prediction
exp = explainer.explain_instance(
sample,
clf.predict_proba,
num_features=8
)
print(f"True label: {y_test.iloc[sample_idx]}")
print(f"Model prediction: {clf.predict([sample])[0]}")
print(f"Memory-based prediction: {memory_predict(sample, memory_bank)[0]}")
# Show the explanation visually
exp.show_in_notebook(show_table=True, show_all=False)


This case demonstrates reduced model confidence (74% vs 96% in the previous example) while maintaining correct predictions. The memory agent continues to use stored experiences for decision-making, showing how the system handles cases with varying degrees of statistical uncertainty by leveraging empirical outcomes from similar past situations.
Step 13: Learning from Mistakes – Memory Expansion
Automatically expanding the memory bank by capturing cases where the static model failed, implementing continuous learning from errors.
from sklearn.metrics.pairwise import cosine_similarity
# Extend memory: add each new "mistake" to memory (simulating ongoing learning)
num_to_check = 100 # Number of test cases to check for mistakes
mistakes = 0
for i in range(num_to_check):
feat = X_test.iloc[i].values
tlabel = y_test.iloc[i]
plabel = clf.predict([feat])[0]
if tlabel != plabel:
add_to_memory(i, feat, tlabel, plabel)
mistakes += 1
print(f"Added {mistakes} new mistake cases to memory. Total memory now has {len(memory_bank)} cases.")

The memory expansion process identified 18 error cases within the first 100 test samples, representing an 18% error rate. These failure cases are now stored with their correct outcomes, enabling the memory system to avoid repeating similar mistakes. The memory bank has grown from 5 to 23 cases, with most new entries representing learning opportunities from model failures.
Step 14: Advanced Cosine Similarity Memory Retrieval
Upgrading the memory system with sophisticated cosine similarity matching for better case retrieval and more flexible similarity assessment.
def memory_predict_cosine(query_features, memory_bank, similarity_threshold=0.97):
"""
Use cosine similarity to search memory bank for the closest case.
If the similarity is above threshold, use that memory's true label.
If not, fall back to the model prediction.
"""
if not memory_bank:
return clf.predict([query_features])[0], False, 0, None
# Stack all memory features in a 2D array for vectorized computation
memory_features = np.stack([case["features"] for case in memory_bank])
similarities = cosine_similarity([query_features], memory_features)[0]
best_index = np.argmax(similarities)
best_similarity = similarities[best_index]
best_case = memory_bank[best_index]
if best_similarity >= similarity_threshold:
adapted_label = best_case["true_label"]
used_memory = True
else:
adapted_label = clf.predict([query_features])[0]
used_memory = False
return adapted_label, used_memory, best_similarity, best_case
# Try it on a "hard" sample — pick a test index where the model was previously wrong?
hard_idx = 25 # Try different values if you like
query_features = X_test.iloc[hard_idx].values
true_lbl = y_test.iloc[hard_idx]
model_prediction = clf.predict([query_features])[0]
memory_result, used_memory, sim, ref_case = memory_predict_cosine(query_features, memory_bank)
print(f"True label: {true_lbl}, Model prediction: {model_prediction}")
print(f"Memory-based prediction (cosine sim): {memory_result} (Used memory: {used_memory}, Similarity: {sim:.2f})")
if used_memory:
print("Memory reference (query_idx, true_label, correct):",
(ref_case['query_idx'], ref_case['true_label'], ref_case['correct']))
else:
print("No sufficiently similar memory case found.")

The advanced cosine similarity system found a perfect match (similarity 1.00) in the memory bank, representing the highest possible similarity score. This sophisticated matching enables finding relevant past experiences even in high-dimensional feature spaces where exact matching would be too restrictive, demonstrating the power of continuous vector similarity for case-based reasoning.
Step 15: Finding Model-Memory Disagreements
Systematically searching for cases where the static model and memory-based agent make opposing predictions to demonstrate adaptive learning advantages.
# Find a test sample where model and memory agent DISAGREE (and memory is used)
disagree_idx = None
for i in range(200): # Search first 200 test indices
sample = X_test.iloc[i].values
model_pred = clf.predict([sample])[0]
mem_pred, used_memory, sim, ref_case = memory_predict_cosine(sample, memory_bank)
if used_memory and model_pred != mem_pred:
disagree_idx = i
break
if disagree_idx is not None:
print(f"Found disagreement at test index: {disagree_idx}")
print(f"True label: {y_test.iloc[disagree_idx]}, Model: {model_pred}, Memory: {mem_pred}, Similarity: {sim:.2f}")
print("Reference memory case:", ref_case)
else:
print("No disagreement found in first 200 cases. Try increasing the range or lowering similarity threshold.")

This represents an ideal demonstration case where the static model incorrectly predicted 0 (≤50K) while the memory agent correctly predicted 1 (>50K). The perfect similarity (1.00) indicates an exact match with a stored case where the original model was wrong (correct=False). This exemplifies how memory-based systems can outperform static models by learning from past mistakes and applying that knowledge to identical future situations.
⚡ Memory Advantage Demonstrated: The memory agent outperformed the static model by learning from past experiences—exactly what Memento achieves without expensive fine-tuning.
Step 16: Comparative LIME Analysis of Disagreement Case
Using LIME to explain both the static model’s incorrect reasoning and the memory agent’s correct decision for comprehensive comparison.
sample_idx = 3
sample = X_test.iloc[sample_idx].values
# Explain with LIME (model prediction)
exp = explainer.explain_instance(
sample,
clf.predict_proba,
num_features=8
)
print("--- Static Model ---")
print(f"True label: {y_test.iloc[sample_idx]}")
print(f"Model prediction: {clf.predict([sample])[0]}")
exp.show_in_notebook(show_table=True, show_all=False)
# Now show: the memory agent would return label 1 (using stored experience)
print("\n--- Memory-adapted (Memento style) ---")
print(f"Memory-based prediction: {memory_predict_cosine(sample, memory_bank)[0]}")
print("Explanation: This decision is based entirely on the experienced outcome seen for this (or nearly this) case in the past—essentially, the agent is 'recalling' the real-world result without re-running model logic.")
# You can also print the features for this case if you'd like to manually compare why memory chose differently!
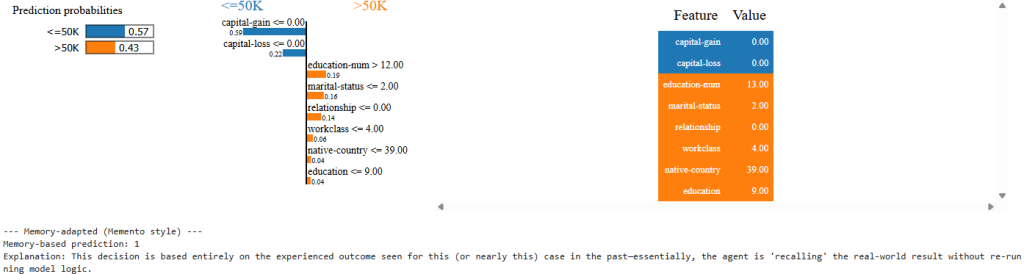
The LIME analysis reveals why the static model failed: despite 43% confidence for >50K income (showing uncertainty), it predicted ≤50K due to conflicting feature signals. The absence of capital gains pushed toward lower income, while higher education suggested higher income. The memory agent bypassed this statistical uncertainty by recalling the actual outcome from an identical previous case, demonstrating how experiential learning can overcome algorithmic limitations in ambiguous situations.
Step 17: Confidence-Weighted Memory System
Implementing sophisticated confidence scoring based on the historical reliability of similar memory cases to enable intelligent memory selection.
import numpy as np
# Add confidence scoring to memory cases based on how often similar cases were correct
def calculate_memory_confidence(memory_bank):
"""
Calculate a confidence score for each memory case based on the success rate
of similar cases (same true_label and correct/incorrect status)
"""
for i, case in enumerate(memory_bank):
# Count similar cases (same true label)
similar_cases = [c for c in memory_bank if c['true_label'] == case['true_label']]
correct_similar = [c for c in similar_cases if c['correct']]
# Confidence = success rate of similar cases
confidence = len(correct_similar) / len(similar_cases) if similar_cases else 0.5
case['confidence'] = confidence
return memory_bank
# Apply confidence scoring
memory_bank = calculate_memory_confidence(memory_bank)
# Show confidence distribution
confidences = [case['confidence'] for case in memory_bank]
correct_cases = [case for case in memory_bank if case['correct']]
incorrect_cases = [case for case in memory_bank if not case['correct']]
print(f"Total memory cases: {len(memory_bank)}")
print(f"Correct cases: {len(correct_cases)} (avg confidence: {np.mean([c['confidence'] for c in correct_cases]):.2f})")
print(f"Incorrect cases: {len(incorrect_cases)} (avg confidence: {np.mean([c['confidence'] for c in incorrect_cases]):.2f})")
print(f"Overall confidence range: {min(confidences):.2f} to {max(confidences):.2f}")

The confidence weighting system reveals important reliability patterns within the memory bank. Only 4 out of 23 cases represent successful original predictions, while 19 represent learning from failures. Correct cases show higher average confidence (0.27) than incorrect cases (0.15), enabling the system to distinguish between trustworthy and unreliable stored experiences. The low overall confidence range reflects that most memory entries come from challenging cases where the static model struggled.
Step 18: Advanced Weighted Memory Prediction
Implementing the most sophisticated memory system that combines both similarity matching and confidence weighting for intelligent decision-making.
def memory_predict_weighted(query_features, memory_bank, similarity_threshold=0.97, confidence_threshold=0.20):
"""
Advanced memory prediction using both cosine similarity AND confidence weighting.
Only use memory if both similarity and confidence are above thresholds.
"""
if not memory_bank:
return clf.predict([query_features])[0], False, 0, None, 0
# Find most similar case
memory_features = np.stack([case["features"] for case in memory_bank])
similarities = cosine_similarity([query_features], memory_features)[0]
best_index = np.argmax(similarities)
best_similarity = similarities[best_index]
best_case = memory_bank[best_index]
best_confidence = best_case['confidence']
# Use memory only if BOTH similarity and confidence are high enough
if best_similarity >= similarity_threshold and best_confidence >= confidence_threshold:
adapted_label = best_case["true_label"]
used_memory = True
else:
adapted_label = clf.predict([query_features])[0]
used_memory = False
return adapted_label, used_memory, best_similarity, best_case, best_confidence
# Test the weighted memory system on our previous disagreement case
test_idx = 3
query_features = X_test.iloc[test_idx].values
true_lbl = y_test.iloc[test_idx]
model_pred = clf.predict([query_features])[0]
weighted_pred, used_mem, sim, ref_case, conf = memory_predict_weighted(query_features, memory_bank)
print(f"True label: {true_lbl}")
print(f"Model prediction: {model_pred}")
print(f"Basic memory prediction: {memory_predict_cosine(query_features, memory_bank)[0]}")
print(f"Weighted memory prediction: {weighted_pred} (Used memory: {used_mem})")
print(f"Similarity: {sim:.2f}, Confidence: {conf:.2f}")
print(f"Memory reference: query_idx={ref_case['query_idx']}, correct={ref_case['correct']}")

This result demonstrates sophisticated meta-cognitive capabilities. Despite finding a perfect similarity match (1.00), the weighted system chose NOT to use memory because the confidence was critically low (0.07). The system recognized that this type of case historically had poor reliability and determined that the static model was statistically more trustworthy than the low-confidence memory entry. This represents advanced meta-learning where the system evaluates its own learning patterns and makes strategic decisions about information source reliability.
🧠 Meta-Learning Achievement: The system demonstrated meta-cognitive abilities—learning about its own learning and making intelligent decisions about when to trust different sources of information.
Conclusion
The Memento paradigm represents a shift from “training then deploying” to “deploying then learning.” This approach enables AI systems to:
- Adapt to new domains without expensive retraining cycles
- Learn from human feedback in real-time
- Maintain transparency through explainable memory retrieval
- Scale efficiently as they encounter more diverse scenarios
Traditional Fine-Tuning Limitations:
- Requires expensive computational resources for model updates
- Risk of catastrophic forgetting when learning new information
- Static knowledge that cannot adapt without full retraining
- No ability to learn from individual interactions or mistakes
Memory-Based Learning Advantages:
- Continuous learning from every interaction without parameter updates
- Retention of all past experiences without forgetting
- Real-time adaptation based on similarity to stored cases
- Sophisticated confidence weighting for intelligent decision-making
- Cost-effective scalability for enterprise applications
Practical Applications
This memory-based approach has immediate applications in:
- Chat-based Analytics: AI agents that improve recommendations based on user feedback
- Customer Support: Systems that learn from successful resolution patterns
- Recommendation Engines: Platforms that adapt to user preferences without retraining
- Process Automation: Workflows that optimize based on historical outcomes