Introduction: Building PaperDrop
PaperDrop is a full stack AI newsletter app designed to help you stay effortlessly updated with the latest tech breakthroughs. This project walks through building an end-to-end system—from user authentication and content curation to beautiful email delivery—leveraging LLMs for automatic summarization and use-case generation. If you want to build an AI newsletter app that fetches, distills, and delivers personalized research insights, this guide is your practical blueprint.
What You’ll Build
- A production-ready AI newsletter app with personalization and automation
- User authentication, history tracking, and preference management
- A full-stack AI-powered newsletter application
- Personalized content delivery based on user preferences
- Automated pipeline for scraping, summarizing, and generating insights
- Clean, structured email delivery system
Project Scope & Requirements of the AI Newsletter App
PaperDrop is designed as a complete, production-style AI newsletter app that brings together content aggregation, personalization, and automated delivery into a single seamless workflow.
Core Capabilities
- Aggregates and summarizes the latest tech research/news using LLMs
- Lets users sign up, set their preferred industry and topics, and receive tailored updates
- Generates clear, actionable plain-English summaries and industry use cases from source articles
- Delivers personal newsletters via email with an optimized, modern layout
- Tracks newsletter history, allows topic changes, and supports one-click unsubscribe
Components of the AI Newsletter App
The system is composed of multiple interconnected components, each responsible for a specific part of the end-to-end workflow.
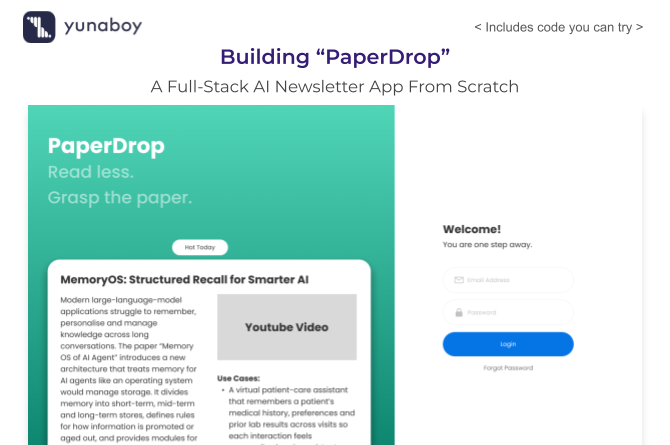
Landing & Auth Page
Welcomes users, explains the purpose, and provides sign-in/sign-up actions.
Dashboard
Main hub for generating and sending newsletters, viewing the latest trending topic, and checking your history.
Preferences
Lets users update their industry focus and preferred AI/news topics for personalized results.
Newsletter Generator
Scrapes fresh articles, uses LLMs to create summaries and use cases, and builds the ready-to-send email.
History & Resend
Displays previously sent newsletters, with options to re-send, download, or delete.
Account Management
Allows for display name updates, sign-out, and quick settings adjustments.
Database Setup for the AI Newsletter App
The backend of this AI newsletter app is powered by Supabase for authentication, storage, and real-time data handling. To power user authentication, personalization, and newsletter tracking, PaperDrop uses Supabase as the backend database.
Supabase (https://supabase.com) provides authentication and database services.
Creating the Required Tables
Create the following tables in your Supabase project:
- Log in to your Supabase dashboard and select your project
- From the left sidebar, click SQL Editor
- In the SQL Editor window that appears, paste the following DDL statements
Database Schema
-- Daily Trending Topic
create table public.daily_trending_topic (
id uuid primary key default uuid_generate_v4(),
topic text not null,
content text not null,
excerpt text not null,
date date not null
);
-- Newsletter History
create table public.newsletter_history (
id uuid primary key default uuid_generate_v4(),
user_email text not null,
topics text[] not null,
content text not null,
subject text not null,
sent_at timestamp with time zone default timezone('utc', now()),
status text not null
);
-- Unsubscribed Users
create table public.unsubscribed_users (
id uuid primary key default uuid_generate_v4(),
email text unique not null,
unsubscribed_at timestamp with time zone default timezone('utc', now())
);
-- User Preference
create table public.user_preference (
id uuid primary key default uuid_generate_v4(),
email text unique not null,
topics jsonb,
user_name text,
created_at timestamp with time zone default timezone('utc', now()),
last_login timestamp with time zone,
industry text,
custom_interest text
);
Execution
Click Run to execute these statements.
Your tables will be created with the exact columns and data types specified.
Folder Structure and Files
The project is organized into a modular structure to clearly separate configuration, business logic, and application layers.
config/
industries.py
sources.py
utils/
ai_curator.py
auth.py
database.py
email_sender.py
scraper.py
.env
app.py
unsubscribe_app.py
README.md
requirements.txtConfiguration Layer
config/industries.py
This module defines the master list of industries that users can select as their primary domain for tailored newsletter content.
This list powers dropdowns and user preferences, enabling sector-specific summaries and use cases.
Purpose
- Centralized reference for all supported industries in the app
- Used in user settings, newsletter customization, and LLM prompts
How it Works
- Makes it easy to add, remove, or update industry options in one place
- Provides a Python list called
INDUSTRIESwith names like “Automotive”, “Healthcare & Pharma”, “Finance & Banking”, etc. - Enables the application to map content and recommendations by user-selected sectors
Implementation
INDUSTRIES = [
"Automotive",
"Aerospace",
"Agriculture",
"Biotechnology",
"Chemicals",
"Construction",
"Consumer Electronics",
"Education",
"Energy & Utilities",
"Finance & Banking",
"Food & Beverage",
"Healthcare & Pharma",
"Hospitality & Travel",
"Information Technology",
"Manufacturing",
"Media & Entertainment",
"Retail",
"Telecommunications",
"Transportation & Logistics",
"Other"
]
config/sources.py
Central library for all content sources used in newsletter curation. Groups URLs and APIs by topic and type, making the scraping layer flexible and easy to extend.
What’s included:
NEWS_SOURCES (dictionary):
- Top-level keys: named after core topics (AI, Machine Learning, Data Science, Technology)
- Each topic contains:
name: Human-readable label for the topiccategories:news: List of major news sites by topicblogs: Official/company blogs relevant to the categorypapers: Academic/API endpoints for latest paperscode: Open-source code, datasets, or Github/PapersWithCode links
rss_sources: RSS feeds for latest articles/blogsapi_sources: APIs for dynamic news/discussion e.g. HackerNews, Reddit
How it works:
- Guides the
scraper.pyfunctions to fetch news, papers, blogs, and code from the best sources for each topic. - Makes it easy to expand, update, or refine where your newsletter gets its data—with just one configuration update.
- Enables personalized, topic-centric curation in the pipeline.
NEWS_SOURCES = {
'AI': {
'name': 'Artificial Intelligence',
'categories': {
'news': [
'https://techcrunch.com/category/artificial-intelligence/',
'https://www.theverge.com/ai-artificial-intelligence',
],
'blogs': [
'https://openai.com/blog/',
'https://www.anthropic.com/news',
'https://www.deepmind.com/blog',
'https://blog.google/technology/ai/',
'https://aws.amazon.com/blogs/machine-learning/',
],
'papers': [
'http://export.arxiv.org/api/query?search_query=cat:cs.AI&start=0&max_results=10&sortBy=submittedDate&sortOrder=descending',
'https://api.semanticscholar.org/graph/v1/paper/search?query=artificial+intelligence&fields=title,abstract,url,year,authors&limit=10',
],
'code': [
'https://api.github.com/search/repositories?q=artificial+intelligence+language:python&sort=stars&order=desc&per_page=10',
'https://paperswithcode.com/api/v1/papers/?q=artificial%20intelligence',
]
},
'rss_sources': [
'https://feeds.feedburner.com/oreilly/radar',
'https://blog.google/technology/ai/rss/',
'https://aws.amazon.com/blogs/machine-learning/feed/',
],
'api_sources': [
'https://hn.algolia.com/api/v1/search_by_date?query=AI&tags=story&hitsPerPage=10',
'https://www.reddit.com/r/artificial/hot.json?limit=5',
]
},
'Machine Learning': {
'name': 'Machine Learning',
'categories': {
'news': [
'https://venturebeat.com/category/ai/',
'https://www.technologyreview.com/topic/artificial-intelligence/',
],
'blogs': [
'https://distill.pub/',
'https://blog.tensorflow.org/',
'https://pytorch.org/blog/',
],
'papers': [
'http://export.arxiv.org/api/query?search_query=cat:cs.LG&start=0&max_results=10&sortBy=submittedDate&sortOrder=descending',
'https://api.semanticscholar.org/graph/v1/paper/search?query=machine+learning&fields=title,abstract,url,year,authors&limit=10',
],
'code': [
'https://api.github.com/search/repositories?q=machine+learning+language:python&sort=stars&order=desc&per_page=10',
'https://paperswithcode.com/api/v1/papers/?q=machine%20learning',
]
},
'rss_sources': [
'https://blog.tensorflow.org/feeds/posts/default',
'https://pytorch.org/feed.xml',
],
'api_sources': [
'https://hn.algolia.com/api/v1/search_by_date?query=machine+learning&tags=story&hitsPerPage=10',
'https://www.reddit.com/r/MachineLearning/hot.json?limit=5',
]
},
'Data Science': {
'name': 'Data Science',
'categories': {
'news': [
'https://www.kdnuggets.com/',
'https://datasciencecentral.com/',
],
'blogs': [
'https://towardsdatascience.com/',
'https://www.kaggle.com/blog',
'https://blog.paperspace.com/',
'https://www.datacamp.com/blog',
],
'papers': [
'http://export.arxiv.org/api/query?search_query=cat:stat.ML&start=0&max_results=10&sortBy=submittedDate&sortOrder=descending',
'https://api.semanticscholar.org/graph/v1/paper/search?query=data+science&fields=title,abstract,url,year,authors&limit=10',
],
'code': [
'https://api.github.com/search/repositories?q=data+science+language:python&sort=stars&order=desc&per_page=10',
'https://www.kaggle.com/datasets',
]
},
'rss_sources': [
'https://towardsdatascience.com/feed',
'https://www.kaggle.com/blog/rss',
'https://blog.paperspace.com/feed/',
],
'api_sources': [
'https://hn.algolia.com/api/v1/search_by_date?query=data+science&tags=story&hitsPerPage=10',
'https://www.reddit.com/r/datascience/hot.json?limit=5',
]
},
'Technology': {
'name': 'Technology',
'categories': {
'news': [
'https://techcrunch.com/',
'https://www.theverge.com/',
'https://arstechnica.com/',
'https://www.wired.com/',
],
'blogs': [
'https://medium.com/tag/technology',
'https://dev.to/t/technology',
],
'papers': [
'http://export.arxiv.org/api/query?search_query=cat:cs.CY&start=0&max_results=10&sortBy=submittedDate&sortOrder=descending',
],
'code': [
'https://api.github.com/search/repositories?q=technology+trending&sort=stars&order=desc&per_page=10',
]
},
'rss_sources': [
'https://techcrunch.com/feed/',
'https://www.theverge.com/rss/index.xml',
'https://feeds.arstechnica.com/arstechnica/index/',
],
'api_sources': [
'https://hn.algolia.com/api/v1/search_by_date?query=technology&tags=story&hitsPerPage=10',
'https://www.reddit.com/r/technology/hot.json?limit=5',
]
}
}
AI Curation Layer
utils/ ai_curator.py
Handles all AI-powered content curation using a large language model (via the Groq API). This module converts raw articles into human-friendly, actionable newsletter content.
Uses LLM APIs like Groq (https://groq.com) for fast inference.
What it does:
- curate_newsletter(articles, user_topics, user_industry):
- Selects the “main” article from the fetched batch.
- Builds a prompt and sends it to the LLM, asking for a plain-language summary (max 1800 characters, no instructions, just summary).
- Cleans up any leftover prompt/instruction noise.
- Requests the LLM to output 2-4 crisp, practical use cases tailored to the user’s industry (again, pure sentences, no headings or fluff, 1800 chars max).
- Cleans up formatting and accidental numbering or leftover prompt text from the LLM.
- Trims the result if over limit, then returns all content as a summary string, a use-cases list, and the article’s URL.
How it works:
- Converts dense, often technical papers or blog posts into highly readable digests.
- Supports sector-specific customizations—use cases are relevant to each user’s working context.
- The rest of the app can display, email, or further process these outputs without post-processing.
Implementation
from groq import Groq
import os
import re
def curate_newsletter(articles: list, user_topics: list, user_industry: str):
"""
Curate a newsletter for a selected topic and industry.
Returns:
summary (str, ≤1800 chars): Plain-language, complete summary.
use_cases (list[str]): Practical use cases, 2–4, combined ≤1800 chars total.
source_url (str): URL for the main featured article/paper.
"""
client = Groq(api_key=os.getenv("GROQ_API_KEY"))
# Use the first/highest-relevance article
main_article = articles[0]
article_text = main_article.get("content", "")
article_title = main_article.get("title", "the research paper")
article_url = main_article.get("url", "#")
# Prompt for concise summary
summary_prompt = (
f"Summarize the following article in plain language for a non-technical audience, "
f"in no more than 1800 characters. Do NOT include instructions or prompt text. "
f"Write only the summary paragraph—do not prepend with 'Summary:' or similar. "
f"Article title: {article_title}\n\n{article_text}"
)
summary_resp = client.chat.completions.create(
model="openai/gpt-oss-20b",
messages=[{"role": "user", "content": summary_prompt}],
max_tokens=2000,
temperature=0.4
)
summary = summary_resp.choices[0].message.content.strip()
# Remove any leading prompt residue
summary = re.sub(r'^(what.*article says.*plain language)?\*?\*?', '', summary, flags=re.I).strip()
if len(summary) > 1800:
summary = summary[:1797]+ "..."
# Prompt for use cases (2–4, plain sentences, no prompt text)
use_cases_prompt = (
f"List 2 to 4 specific, practical use cases of the above research in the {user_industry} industry. "
f"Each use case should be clear, in 1-2 sentences. Total length under 1800 characters. "
f"Do NOT include instructions, headings, or introductory text. Output ONLY the actual use cases."
)
use_cases_resp = client.chat.completions.create(
model="openai/gpt-oss-20b",
messages=[
{"role": "user", "content": summary_prompt},
{"role": "assistant", "content": summary},
{"role": "user", "content": use_cases_prompt}
],
max_tokens=1800,
temperature=0.45
)
raw_uses = use_cases_resp.choices[0].message.content.strip()
# Split by lines, remove any numbering/prompt spills, filter empties
use_cases = [u.lstrip("0123456789.:- ").strip() for u in re.split(r'\n|(?=Use Case)', raw_uses) if u.strip()]
# Remove any heading/intro lines accidentally present
use_cases = [u for u in use_cases if not re.match(r'^(practical|use\s?case).*:', u.lower())]
# Re-trim if too long
total = sum(len(u) for u in use_cases)
if total > 1800:
trimmed, accum = [], 0
for u in use_cases:
if accum + len(u) <= 1800:
trimmed.append(u)
accum += len(u)
use_cases = trimmed
return summary, use_cases, article_url
Authentication Layer
utils/ auth.py
Handles all user authentication and session control for the app, integrating securely with Supabase as the backend service.
Key Functions:
- Session State Setup
init_auth(): Initializes Streamlit session variables for auth state and user info.
- User Registration and Login
sign_up(email, password): Signs up a new user using Supabase Auth API; returns status and user.sign_in(email, password): Logs in user; updates Streamlit session if successful.
- Session Management
sign_out(): Logs the user out in both Supabase and Streamlit session.reset_password(email): Triggers a password reset email through Supabase.
- Session State Utilities
get_current_user(): Returns current user object or None.is_authenticated(): Returns True if user is logged in and session valid.get_user_email(): Returns logged-in user’s email for use in UI and DB queries.handle_auth_state_change(): Checks/updates auth state on app reload, for seamless single sign-on after verification.
What it does:
- Securely creates, authenticates, and manages users—with no passwords exposed in frontend code.
- Persists auth info and user state in session for smooth navigation between pages and reruns.
- Bridges Streamlit widgets, app state, and the underlying Supabase auth APIs.
Implementation
import streamlit as st
from supabase import create_client
import os
from dotenv import load_dotenv
load_dotenv()
# Initialize Supabase client
supabase = create_client(
os.getenv("SUPABASE_URL"),
os.getenv("SUPABASE_KEY")
)
def init_auth():
"""Initialize authentication session state"""
if 'authenticated' not in st.session_state:
st.session_state.authenticated = False
if 'user' not in st.session_state:
st.session_state.user = None
if 'user_email' not in st.session_state:
st.session_state.user_email = None
def sign_up(email: str, password: str):
"""Sign up a new user"""
try:
response = supabase.auth.sign_up({
"email": email,
"password": password
})
if response.user:
return {
"success": True,
"message": "Account created successfully! Please check your email to verify your account.",
"user": response.user
}
else:
return {
"success": False,
"message": "Failed to create account. Please try again."
}
except Exception as e:
return {
"success": False,
"message": f"Error creating account: {str(e)}"
}
def sign_in(email: str, password: str):
"""Sign in an existing user"""
try:
response = supabase.auth.sign_in_with_password({
"email": email,
"password": password
})
if response.user:
# Update session state
st.session_state.authenticated = True
st.session_state.user = response.user
st.session_state.user_email = response.user.email
return {
"success": True,
"message": "Signed in successfully!",
"user": response.user
}
else:
return {
"success": False,
"message": "Invalid email or password."
}
except Exception as e:
return {
"success": False,
"message": f"Error signing in: {str(e)}"
}
def sign_out():
"""Sign out the current user"""
try:
supabase.auth.sign_out()
# Clear session state
st.session_state.authenticated = False
st.session_state.user = None
st.session_state.user_email = None
return True
except Exception as e:
st.error(f"Error signing out: {str(e)}")
return False
def reset_password(email: str):
"""Send password reset email"""
try:
supabase.auth.reset_password_email(email)
return {
"success": True,
"message": "Password reset email sent! Check your inbox."
}
except Exception as e:
return {
"success": False,
"message": f"Error sending reset email: {str(e)}"
}
def get_current_user():
"""Get current authenticated user"""
return st.session_state.user if st.session_state.authenticated else None
def is_authenticated():
"""Check if user is authenticated"""
return st.session_state.authenticated
def get_user_email():
"""Get current user's email"""
return st.session_state.user_email if st.session_state.authenticated else None
def handle_auth_state_change():
"""Handle authentication state changes"""
try:
# Check if there's a session in the URL (for email verification)
session = supabase.auth.get_session()
if session:
st.session_state.authenticated = True
st.session_state.user = session.user
st.session_state.user_email = session.user.email
except:
# No valid session found
pass
Database Layer
utils/ database.py
Contains all functions for reading/writing user data, newsletter activity, and trending topics to Supabase tables.
Key responsibilities:
- User Preferences
save_preferences(email, topics, industry, custom_interest): Creates or updates a user’s topics, industry, or custom interests.get_user_preferences(email): Fetches a user’s stored preferences.clear_user_preferences(email): Removes all current interests for a user.
- User Profile Management
update_user_name(email, name): Changes user’s display name.get_user_profile(email): Fetches the complete profile (name, topics, etc.).update_last_login(email): Records the latest login timestamp for tracking engagement.
- Newsletter Logging
save_newsletter_history(email, topics, content, subject, status): Logs each send for replay, status, or reference.get_newsletter_history(email, limit): Lists a user’s past newsletters, ordered newest first.
- Unsubscribe & Compliance
save_unsubscribe(email): Logs when a user opts out for compliance/tracking.
- Trending Topic Feature
save_trending_topic(topic, content, excerpt): Records or updates today’s trending tech topic in a special Supabase table.get_trending_topic(): Reads today’s trending topic for daily highlights in the UI.
How it works:
- Every function safely handles errors and tries to update or return just the relevant data.
- The approach cleanly separates all DB reads/writes from business logic or UI files.
- API calls use Supabase’s Python client, always authenticating using project secrets.
Implementation
from supabase import create_client
import os
from dotenv import load_dotenv
from datetime import datetime, date
load_dotenv()
supabase = create_client(
os.getenv("SUPABASE_URL"),
os.getenv("SUPABASE_KEY")
)
def save_preferences(email: str, topics: list, industry: str = None, custom_interest: str = None):
"""Save or update user preferences including topics, industry, and custom interest"""
try:
payload = {'topics': topics}
if industry is not None:
payload['industry'] = industry
if custom_interest is not None:
payload['custom_interest'] = custom_interest
existing = supabase.table('user_preference').select('id').eq('email', email).execute()
if existing.data:
supabase.table('user_preference').update(payload).eq('email', email).execute()
else:
payload['email'] = email
supabase.table('user_preference').insert(payload).execute()
return True
except Exception as e:
print(f"Error saving preferences: {e}")
return False
def get_user_preferences(email: str):
"""Get user preferences by email"""
try:
response = supabase.table('user_preference')\
.select("*")\
.eq('email', email)\
.execute()
return response.data[0] if response.data else None
except Exception as e:
print(f"Error: {e}")
return None
def save_newsletter_history(email: str, topics: list, content: str, subject: str, status: str = 'sent'):
"""Save newsletter to history"""
try:
supabase.table('newsletter_history').insert({
'user_email': email,
'topics': topics,
'content': content,
'subject': subject,
'status': status
}).execute()
return True
except Exception as e:
print(f"Error saving newsletter history: {e}")
return False
def get_newsletter_history(email: str, limit: int = 10):
"""Get user's newsletter history"""
try:
response = supabase.table('newsletter_history')\
.select("*")\
.eq('user_email', email)\
.order('sent_at', desc=True)\
.limit(limit)\
.execute()
return response.data if response.data else []
except Exception as e:
print(f"Error fetching newsletter history: {e}")
return []
def update_user_name(email: str, name: str):
"""Update user's display name"""
try:
supabase.table('user_preference').update({
'user_name': name
}).eq('email', email).execute()
return True
except Exception as e:
print(f"Error updating user name: {e}")
return False
def get_user_profile(email: str):
"""Get complete user profile including name, topics, industry, and custom interest"""
try:
response = supabase.table('user_preference')\
.select("*")\
.eq('email', email)\
.execute()
return response.data[0] if response.data else None
except Exception as e:
print(f"Error fetching user profile: {e}")
return None
def update_last_login(email: str):
"""Update user's last login timestamp"""
try:
supabase.table('user_preference').update({
'last_login': datetime.now().isoformat()
}).eq('email', email).execute()
return True
except Exception as e:
print(f"Error updating last login: {e}")
return False
def save_unsubscribe(email: str):
"""Save the unsubscribed email and timestamp"""
try:
supabase.table('unsubscribed_users').insert({
'email': email
}).execute()
return True
except Exception as e:
print(f"Error saving unsubscribe: {e}")
return False
def clear_user_preferences(email: str):
"""Remove all topics, industry, and custom_interest for the user (keep the row for reactivation)"""
try:
supabase.table('user_preference').update({
'topics': [],
'industry': None,
'custom_interest': None
}).eq('email', email).execute()
return True
except Exception as e:
print(f"Error clearing user preferences: {e}")
return False
def save_trending_topic(topic: str, content: str, excerpt: str):
"""Store or update the trending topic for today."""
try:
today = str(date.today())
existing = supabase.table('daily_trending_topic').select('id').eq('date', today).execute()
if existing.data:
supabase.table('daily_trending_topic').update({
'topic': topic,
'content': content,
'excerpt': excerpt
}).eq('date', today).execute()
else:
supabase.table('daily_trending_topic').insert({
'topic': topic,
'content': content,
'excerpt': excerpt,
'date': today
}).execute()
return True
except Exception as e:
print(f"Error saving trending topic: {e}")
return False
def get_trending_topic():
"""Get today's trending topic (single dict or None)"""
try:
today = str(date.today())
res = supabase.table('daily_trending_topic').select('*').eq('date', today).limit(1).execute()
return res.data[0] if res.data else None
except Exception as e:
print(f"Error fetching trending topic: {e}")
return None
Email Delivery
utils/ email_sender.py
Handles the process of formatting and sending newsletters as stylish HTML emails using Resend as the transactional mail backend.
Emails are sent using Resend (https://resend.com).
Key routines and flow:
- API Key Setup
- Loads Resend API key from environment for secure, direct sending.
- send_newsletter(to_email, paper_summary, topics, use_cases, source_url):
- Generates a dynamic subject line featuring “PaperDrop” and the chosen topic.
- Combines all use cases into a single block and ensures the text never exceeds the set character allowance.
- Builds a visually appealing, responsive HTML email with a gradient background, rounded card, two-column layout for summary and use cases, and a footer with primary actions.
- Sends the email via the Resend API (with error handling).
- Records the result in newsletter history (calls
save_newsletter_historywith metadata and send status), keeping both successful and failed send attempts auditable.
What it does:
- All outgoing user-facing content is consistently formatted and delivered, emphasizing clarity and professional branding.
- Every newsletter sent (or failed) is tracked for re-sending, compliance, and future analytics.
Implementation
import os
import resend
from utils.database import save_newsletter_history
resend.api_key = os.getenv("RESEND_API_KEY")
def send_newsletter(to_email: str,
paper_summary: str,
topics: list,
use_cases: list,
source_url: str):
"""
Send a styled HTML newsletter via Resend.
- paper_summary: complete summary ≤600 characters
- topics: list of topic strings
- use_cases: list of detailed use case strings (total ≤600 chars)
- source_url: URL of original paper
"""
subject = f"📰 Just Landed: Your PaperDrop – {topics[0]}"
# Build use-cases HTML for right column
use_cases_combined = " ".join(use_cases)
if len(use_cases_combined) > 600:
# Truncate with ellipsis if exceeds limit
use_cases_combined = use_cases_combined[:597] + "..."
html_content = f"""
<html>
<body style="
margin:0; padding:0;
background: linear-gradient(to bottom, #50D5B7, #067D68);
">
<div style="
max-width:600px; width:90%; margin:0 auto;
background:white; border-radius:16px; overflow:hidden;
">
<!-- Header -->
<div style="
padding:24px; text-align:center; border-bottom:1px solid #eee;
">
<h1 style="margin:0; font-size:24px; color:#165146;">
Just Landed: Your PaperDrop
</h1>
<p style="margin:8px 0 0; font-size:16px; color:#555;">
Read less. Grasp the paper.
</p>
</div>
<!-- Content Two Columns -->
<div style="
display:flex; flex-wrap:wrap; padding:24px; gap:16px;
">
<!-- Left column: summary -->
<div style="flex:1 1 280px; min-width:280px;">
<p style="
margin:0; font-size:14px; line-height:1.5; color:#333;
">
{paper_summary}
</p>
</div>
<!-- Right column: use cases -->
<div style="flex:1 1 280px; min-width:280px;">
<div style="
background:#f6f8fa;
border-radius:8px;
padding:16px;
font-size:14px;
color:#333;
min-height:100px;
line-height:1.5;
">
<b>Practical Use Cases:</b><br>
{use_cases_combined}
</div>
</div>
</div>
<!-- Footer Links -->
<div style="
padding:16px; text-align:center; border-top:1px solid #eee;
">
<a href="{source_url}"
style="margin:0 8px; color:#667eea; text-decoration:none;">
Source
</a>
|
<a href="https://your-app-url.com/settings"
style="margin:0 8px; color:#667eea; text-decoration:none;">
Change Topic Preference
</a>
|
<a href="https://your-app-url.com/unsubscribe?email={to_email}"
style="margin:0 8px; color:#e53935; text-decoration:none;">
Unsubscribe
</a>
</div>
</div>
</body>
</html>
"""
try:
resend.Emails.send({
"from": "onboarding@resend.dev",
"to": to_email,
"subject": subject,
"html": html_content
})
save_newsletter_history(to_email, topics, paper_summary, subject, 'sent')
return {"success": True, "message": "Newsletter sent successfully!"}
except Exception:
save_newsletter_history(to_email, topics, paper_summary, subject, 'failed')
return {"success": False, "message": "Failed to send newsletter."}
Scraper Engine
utils/ scraper.py
Handles scraping, parsing, and deduplication of news, blog, academic, and code sources for each supported topic, enabling diverse, high-quality content in every newsletter.
Main tasks and flow:
- Source Processing
- Uses custom handlers for each source type: news/blogs, APIs/HackerNews, Reddit, academic (arXiv, Semantic Scholar), and code repos (GitHub, Papers With Code).
- Extracts fresh URLs/content using topic-specific selectors or public APIs.
- Article Extraction
- Gathers and cleans article content (HTML scraping, summary extraction, metadata).
- Handles common site structures and multi-paragraph extraction.
- Falls back to meta or page text if main content is missing.
- Deduplication & Selection
- Deduplicates by title similarity to maximize uniqueness in each newsletter.
- Allows for priority: newest, most starred/voted, or most relevant articles.
- Main Interface
scrape_sources(category, max_articles): One call to fetch all relevant content for a newsletter topic, no matter the source type.
- Resiliency
- Skips broken/slow sources, handles missing data, and suppresses SSL verification warnings for broader coverage.
- Always tries to return as many diverse articles as possible.
Implementation
import requests
from bs4 import BeautifulSoup
import json
from datetime import datetime
import urllib3
from xml.etree import ElementTree as ET
from urllib.parse import urlparse, urljoin
# Disable SSL warnings
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def extract_domain(url):
"""Extract domain name from URL"""
try:
domain = urlparse(url).netloc
return domain.replace('www.', '')
except:
return url[:30]
def deduplicate_articles(articles):
"""Remove duplicate articles based on title similarity"""
unique_articles = []
seen_titles = set()
for article in articles:
title_key = article['title'].lower()[:50]
if title_key not in seen_titles:
seen_titles.add(title_key)
unique_articles.append(article)
return unique_articles
def get_article_content_safe(url):
"""Safely get article content with error handling"""
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36'
}
response = requests.get(url, headers=headers, verify=False, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
content_selectors = [
'.article-body p', '.story-body p', '.article-content p', '.post-content p',
'.entry-content p', '.content p', '.story p', '.article p',
'article p', 'main p', '.main p', 'p'
]
for selector in content_selectors:
paragraphs = soup.select(selector)
if paragraphs:
content_parts = []
for p in paragraphs[:5]:
text = p.get_text(strip=True)
if len(text) > 50:
content_parts.append(text)
if content_parts and len(' '.join(content_parts)) > 200:
return ' '.join(content_parts)
meta_desc = soup.find('meta', attrs={'name': 'description'})
if meta_desc and meta_desc.get('content'):
desc = meta_desc.get('content').strip()
if len(desc) > 100:
return desc
text = soup.get_text()
if len(text) > 100:
lines = text.split('\n')
clean_lines = [line.strip() for line in lines if len(line.strip()) > 50]
if clean_lines:
return ' '.join(clean_lines[:3])
except Exception as e:
print(f" ⚠️ Error getting content from {url}: {e}")
return ""
def scrape_web_source(source, headers):
"""Scrape news/blog websites"""
articles = []
try:
response = requests.get(source['url'], headers=headers, timeout=10, verify=False)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
link_selectors = [
'article a', 'h2 a', 'h3 a', '.headline a', '.title a',
'.post-title a', '.entry-title a', '.article-title a'
]
for selector in link_selectors:
links = soup.select(selector)
if links:
for link in links[:3]:
title = link.get_text(strip=True)
url = link.get('href', '')
if url.startswith('/'):
url = urljoin(source['url'], url)
if title and url and len(title) > 20:
content = get_article_content_safe(url)
if content:
articles.append({
'source': url,
'title': title,
'content': content[:1500],
'published': None,
'type': source['type']
})
print(f" ✅ Found: {title[:50]}...")
break
except Exception as e:
print(f" ⚠️ Web scraping error: {e}")
return articles
def scrape_api_source(source, headers):
"""Scrape from API source (like Hacker News)"""
articles = []
try:
response = requests.get(source['url'], headers=headers, timeout=10)
response.raise_for_status()
data = response.json()
if 'hits' in data:
for hit in data['hits'][:3]:
title = hit.get('title', '')
url = hit.get('url', '')
points = hit.get('points', 0)
created_at = hit.get('created_at', '')
if title and url and points > 5:
content = get_article_content_safe(url)
if content:
articles.append({
'source': url,
'title': title,
'content': content[:1500],
'published': created_at,
'type': 'news'
})
print(f" ✅ Found: {title[:50]}...")
except Exception as e:
print(f" ⚠️ API scraping error: {e}")
return articles
def scrape_reddit_source(source, headers):
"""Scrape from Reddit source"""
articles = []
try:
response = requests.get(source['url'], headers=headers, timeout=10)
response.raise_for_status()
data = response.json()
if 'data' in data and 'children' in data['data']:
for post in data['data']['children'][:3]:
post_data = post.get('data', {})
title = post_data.get('title', '')
url = post_data.get('url', '')
score = post_data.get('score', 0)
selftext = post_data.get('selftext', '')
if title and url and score > 10:
if selftext and len(selftext) > 100:
content = selftext
else:
content = get_article_content_safe(url)
if not content or len(content) < 100:
content = f"Recent discussion: {title}. This post discusses important developments in the field."
articles.append({
'source': url,
'title': title,
'content': content[:1500],
'published': None,
'type': 'discussion'
})
print(f" ✅ Found: {title[:50]}...")
except Exception as e:
print(f" ⚠️ Reddit scraping error: {e}")
return articles
def scrape_arxiv_source(source, headers):
"""Scrape from ArXiv source"""
articles = []
try:
response = requests.get(source['url'], headers=headers, timeout=10)
response.raise_for_status()
root = ET.fromstring(response.content)
ns = {'atom': 'http://www.w3.org/2005/Atom'}
for entry in root.findall('atom:entry', ns)[:3]:
title_elem = entry.find('atom:title', ns)
summary_elem = entry.find('atom:summary', ns)
link_elem = entry.find('atom:link[@type="text/html"]', ns)
published_elem = entry.find('atom:published', ns)
if title_elem is not None and summary_elem is not None:
title = title_elem.text.strip()
summary = summary_elem.text.strip()
url = link_elem.get('href') if link_elem is not None else ''
published = published_elem.text[:10] if published_elem is not None else None
articles.append({
'source': url,
'title': title,
'content': f"ArXiv Paper\n\nAbstract: {summary[:1200]}",
'published': published,
'type': 'paper'
})
print(f" ✅ Found paper: {title[:50]}...")
except Exception as e:
print(f" ⚠️ ArXiv scraping error: {e}")
return articles
def scrape_semantic_scholar_source(source, headers):
"""Scrape from Semantic Scholar API"""
articles = []
try:
response = requests.get(source['url'], headers=headers, timeout=10)
response.raise_for_status()
data = response.json()
for paper in data.get('data', [])[:3]:
title = paper.get('title', '')
abstract = paper.get('abstract', '')
url = paper.get('url', '')
authors = paper.get('authors', [])
year = paper.get('year', '')
if title and abstract:
author_names = [author.get('name', '') for author in authors[:3]]
author_str = ', '.join(author_names)
articles.append({
'source': url or f"https://semanticscholar.org/paper/{paper.get('paperId', '')}",
'title': title,
'content': f"Authors: {author_str} ({year})\n\nAbstract: {abstract[:1200]}",
'published': str(year) if year else None,
'type': 'paper'
})
print(f" ✅ Found paper: {title[:50]}...")
except Exception as e:
print(f" ⚠️ Semantic Scholar scraping error: {e}")
return articles
def scrape_github_source(source, headers):
"""Scrape from GitHub API"""
articles = []
try:
headers.update({'Accept': 'application/vnd.github.v3+json'})
response = requests.get(source['url'], headers=headers, timeout=10)
response.raise_for_status()
data = response.json()
for repo in data.get('items', [])[:3]:
name = repo.get('name', '')
description = repo.get('description', '')
url = repo.get('html_url', '')
stars = repo.get('stargazers_count', 0)
language = repo.get('language', '')
updated = repo.get('updated_at', '')
if name and description and stars > 10:
content = f"Language: {language}\nStars: {stars:,}\nLast updated: {updated[:10]}\n\nDescription: {description}"
articles.append({
'source': url,
'title': f"GitHub: {name}",
'content': content,
'published': updated[:10] if updated else None,
'type': 'code'
})
print(f" ✅ Found repo: {name}")
except Exception as e:
print(f" ⚠️ GitHub scraping error: {e}")
return articles
def scrape_paperswithcode_source(source, headers):
"""Scrape from Papers With Code API"""
articles = []
try:
response = requests.get(source['url'], headers=headers, timeout=10)
response.raise_for_status()
data = response.json()
for paper in data.get('results', [])[:3]:
title = paper.get('title', '')
abstract = paper.get('abstract', '')
url = paper.get('url_abs', '') or paper.get('url_pdf', '')
if title and abstract:
articles.append({
'source': url,
'title': title,
'content': f"Paper with Code Implementation\n\nAbstract: {abstract[:1200]}",
'published': None,
'type': 'paper_code'
})
print(f" ✅ Found paper+code: {title[:50]}...")
except Exception as e:
print(f" ⚠️ Papers With Code scraping error: {e}")
return articles
def scrape_enhanced_source(source):
"""Scrape from an enhanced source based on type"""
articles = []
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36'
}
if source['type'] in ['news', 'blog']:
articles = scrape_web_source(source, headers)
elif source['type'] == 'api':
articles = scrape_api_source(source, headers)
elif source['type'] == 'reddit':
articles = scrape_reddit_source(source, headers)
elif source['type'] == 'arxiv':
articles = scrape_arxiv_source(source, headers)
elif source['type'] == 'semantic_scholar':
articles = scrape_semantic_scholar_source(source, headers)
elif source['type'] == 'github':
articles = scrape_github_source(source, headers)
elif source['type'] == 'paperswithcode':
articles = scrape_paperswithcode_source(source, headers)
except Exception as e:
print(f" ❌ Error scraping {source['name']}: {e}")
return articles
def get_enhanced_sources(category):
"""Get all enhanced sources including categorized sources"""
from config.sources import NEWS_SOURCES
category_data = NEWS_SOURCES.get(category, {})
sources = []
categories = category_data.get('categories', {})
for url in categories.get('news', []):
sources.append({
'name': f'News: {extract_domain(url)}',
'url': url,
'type': 'news'
})
for url in categories.get('blogs', []):
sources.append({
'name': f'Blog: {extract_domain(url)}',
'url': url,
'type': 'blog'
})
for url in categories.get('papers', []):
if 'arxiv.org' in url:
sources.append({
'name': f'ArXiv {category}',
'url': url,
'type': 'arxiv'
})
elif 'semanticscholar.org' in url:
sources.append({
'name': f'Semantic Scholar {category}',
'url': url,
'type': 'semantic_scholar'
})
for url in categories.get('code', []):
if 'github.com' in url:
sources.append({
'name': f'GitHub {category}',
'url': url,
'type': 'github'
})
elif 'paperswithcode.com' in url:
sources.append({
'name': f'Papers With Code {category}',
'url': url,
'type': 'paperswithcode'
})
api_sources = category_data.get('api_sources', [])
for url in api_sources:
if 'hn.algolia.com' in url:
sources.append({
'name': f'Hacker News {category}',
'url': url,
'type': 'api'
})
elif 'reddit.com' in url:
sources.append({
'name': f'Reddit {category}',
'url': url,
'type': 'reddit'
})
elif 'arxiv.org' in url:
sources.append({
'name': f'ArXiv {category}',
'url': url,
'type': 'arxiv'
})
return sources
def scrape_sources(category: str, max_articles=5):
"""Enhanced scraper that gets content from news, blogs, papers, and code repositories"""
print(f"🔍 Scraping recent {category} content from all sources...")
articles = []
all_sources = get_enhanced_sources(category)
for source in all_sources:
try:
print(f"📰 Checking: {source['name']}")
articles_from_source = scrape_enhanced_source(source)
articles.extend(articles_from_source)
if len(articles) >= max_articles * 2:
break
except Exception as e:
print(f" ⚠️ Failed to scrape {source['name']}: {e}")
unique_articles = deduplicate_articles(articles)
print(f"✅ Found {len(unique_articles)} unique articles from all sources")
return unique_articles[:max_articles]
.env
Store all sensitive API keys and project URLs needed for external dependencies in a secure, environment-variable format.
GROQ_API_KEY=your_groq_api_key_here
RESEND_API_KEY=your_resend_api_key_here
SUPABASE_URL=your_supabase_url_here
SUPABASE_KEY=your_supabase_service_role_key_hereMain App: Building the AI Newsletter App Interface
This is the core application layer where the AI newsletter app comes together—handling UI, personalization, and orchestration.
app.py
Main Streamlit app for PaperDrop, orchestrating authentication, personalized dashboard, newsletter generation, and user settings.
Major components:
- Auth UI
- Renders sign-in, sign-up, and password reset forms.
- Handles user registration, login, and session state using Supabase.
- Personal Dashboard
- Greets logged-in users by name.
- Shows today’s trending tech topic (with excerpt and send option).
- Lets users generate and send custom newsletters from chosen topics.
- Displays email delivery status and newsletter preview after send.
- Shows past newsletter history with re-send, download, and (future) delete actions.
- Account Settings
- Allows updating display name via form.
- Lets users view and update industry/topic preferences.
- Includes sign out and quick navigation to change topics or unsubscribe.
- Newsletter Pipeline
- Uses scraping, AI curation, and email sending modules to produce newsletters from source content.
- Tracks real delivery outcomes and logs newsletter history.
- Routing Logic
- Runs the dashboard for authenticated users, or the auth page for guests.
- Handles session/init for seamless navigation and security.
Implementation
import streamlit as st
import streamlit_shadcn_ui as ui
from config.sources import NEWS_SOURCES
from config.industries import INDUSTRIES
from utils.database import (
save_preferences,
get_user_profile,
get_newsletter_history,
update_user_name,
update_last_login,
get_trending_topic,
save_trending_topic
)
from utils.scraper import scrape_sources
from utils.ai_curator import curate_newsletter
from utils.email_sender import send_newsletter
from utils.auth import (
init_auth, sign_up, sign_in, sign_out, reset_password,
is_authenticated, get_user_email, handle_auth_state_change
)
from datetime import date
import base64
st.set_page_config(page_title="PaperDrop", page_icon="📰", layout="wide")
# Initialize authentication
init_auth()
handle_auth_state_change()
def show_auth_page():
colA, colB = st.columns([2, 1], gap="large")
with colA:
st.markdown(
"<h1 style='font-size:48px; color:#333;'>PaperDrop</h1>"
"<p style='font-size:18px; color:#555; max-width:400px;'>Read less. Grasp the paper.</p>",
unsafe_allow_html=True
)
with colB:
st.markdown(
"""
<div style="background-color:#FFF9C4; padding:20px; border-radius:8px; box-shadow: 0 2px 6px rgba(0,0,0,0.1);">
""",
unsafe_allow_html=True
)
auth_tab, signup_tab = st.tabs(["Sign In", "Sign Up"])
with auth_tab:
st.subheader("Sign In")
with st.form("signin_form"):
email = st.text_input("Email", placeholder="your@email.com")
password = st.text_input("Password", type="password")
submit = st.form_submit_button("Sign In")
if submit:
if email and password:
result = sign_in(email, password)
if result["success"]:
st.success(result["message"])
st.rerun()
else:
st.error(result["message"])
else:
st.error("Please fill in all fields")
if st.button("Forgot Password?"):
reset_email = st.text_input(
"Enter your email for password reset", placeholder="your@email.com"
)
if reset_email:
result = reset_password(reset_email)
if result["success"]:
st.success(result["message"])
else:
st.error(result["message"])
with signup_tab:
st.subheader("Sign Up")
with st.form("signup_form"):
new_email = st.text_input(
"Email", placeholder="your@email.com", key="signup_email"
)
new_password = st.text_input(
"Password", type="password", key="signup_password"
)
confirm_password = st.text_input(
"Confirm Password", type="password", key="signup_confirm"
)
submit_signup = st.form_submit_button("Sign Up")
if submit_signup:
if new_email and new_password and confirm_password:
if new_password == confirm_password:
if len(new_password) >= 6:
result = sign_up(new_email, new_password)
if result["success"]:
save_preferences(new_email, [], None, None)
st.success(result["message"])
else:
st.error(result["message"])
else:
st.error("Password must be at least 6 characters long")
else:
st.error("Passwords do not match")
else:
st.error("Please fill in all fields")
st.markdown("</div>", unsafe_allow_html=True)
def show_personal_dashboard():
user_email = get_user_email()
update_last_login(user_email)
profile = get_user_profile(user_email) or {}
user_name = profile.get('user_name', 'Friend')
current_industry = profile.get('industry', INDUSTRIES[-1])
current_topic = profile.get('topics', [list(NEWS_SOURCES.keys())[0]])[0] if profile.get('topics') else list(NEWS_SOURCES.keys())[0]
trending = get_trending_topic()
if not trending:
trending_topic = "AI in Finance"
trending_content = (
"Today's trending topic highlights how AI is transforming financial services"
"—from algorithmic trading to intelligent risk management, compliance automation,"
"and the rise of personalized banking. Leading banks deploy NLP for fraud detection,"
"chatbots for customer engagement, and AI-powered credit scoring models."
"Regulatory tech (RegTech) is also advancing, using machine learning to flag suspicious"
"transactions and optimize reporting. As adoption grows, critical debates continue"
"around explainability and ethics. The excerpt reflects the biggest innovations and challenges shaping AI adoption in finance."
)
trending_excerpt = " ".join(trending_content.split()[:150]) + "..."
save_trending_topic(trending_topic, trending_content, trending_excerpt)
trending = get_trending_topic()
st.title(f"👋 {user_name}, here’s your PaperDrop.")
col1, col2 = st.columns([2, 1])
with col1:
st.markdown("---")
st.markdown("### 🔥 Trending Topic Today")
st.write(f"**{trending['topic']}**")
with st.expander("Click for excerpt/more"):
st.write(trending['excerpt'])
if st.button("Send this topic as newsletter", key="send_trending"):
# For trending, use Groq LLM to generate summary/use cases
articles = [{"title": trending['topic'], "content": trending['content'], "url": "#"}]
summary, use_cases, source_url = curate_newsletter(articles, [trending['topic']], current_industry)
result = send_newsletter(
user_email,
summary,
[trending['topic']],
use_cases,
source_url
)
if result and result.get('success'):
st.success("You received the trending topic in your email!")
else:
st.error("Sending failed. Try again later.")
st.markdown("---")
st.subheader("✨ Generate New Newsletter")
with st.form("generate_newsletter_form"):
choice = st.selectbox(
"Choose topic for today's newsletter",
options=[current_topic] + [t for t in list(NEWS_SOURCES.keys()) if t != current_topic]
)
if st.form_submit_button("🚀 Generate & Send Newsletter"):
progress = st.progress(0, text="🔍 Starting up...")
articles = scrape_sources(choice, max_articles=5)
if not articles:
progress.empty()
st.warning("⚠️ No articles found for this topic.")
else:
progress.progress(50, "🤖 Curating content with AI...")
summary, use_cases, source_url = curate_newsletter(articles, [choice], current_industry)
progress.progress(85, "📧 Sending newsletter...")
result = send_newsletter(
user_email,
summary,
[choice],
use_cases,
source_url
)
progress.progress(100, "✅ Done!")
progress.empty()
if result and result['success']:
st.success("✅ Newsletter generated and sent!")
st.markdown("### Preview:")
st.markdown(summary)
st.markdown("##### Practical Use Cases:")
st.markdown("<ul>" + "".join([f"<li>{uc}</li>" for uc in use_cases]) + "</ul>", unsafe_allow_html=True)
st.markdown(f"Source: {source_url}")
st.toast("Process finished!", icon="🎉")
st.rerun()
else:
st.error("Something went wrong. Please try again later.")
st.toast("Something went wrong!", icon="⚠️")
st.subheader("📬 Your Newsletter History")
history = get_newsletter_history(user_email, limit=10)
if history:
for idx, nl in enumerate(history):
with st.expander(f"📰 {nl['subject']} - {nl['sent_at'][:10]}", expanded=(idx==0)):
st.write(f"**Topics:** {', '.join(nl['topics'])}")
st.write(f"**Status:** {nl['status'].upper()}")
st.write(f"**Sent:** {nl['sent_at']}")
st.markdown("---")
snippet = nl['content'][:500] + "..." if len(nl['content'])>500 else nl['content']
st.markdown(snippet)
c1, c2, c3 = st.columns(3)
with c1:
# For a real resend, you might want to retrieve original summary/use_cases/source.
# Here, a placeholder version:
summary = "Resent summary placeholder."
use_cases = ["Resent use case 1.", "Resent use case 2."]
source_url = "https://your-source-link.com/"
if st.button("📧 Resend", key=f"resend_{nl['id']}"):
r = send_newsletter(
user_email,
summary,
nl['topics'],
use_cases,
source_url
)
if r['success']:
st.success("Newsletter resent!")
st.rerun()
else:
st.error("Something went wrong. Please try again later.")
with c2:
txt = f"{nl['subject']}\n\n{nl['content']}"
b64 = base64.b64encode(txt.encode()).decode()
link = f'<a href="data:text/plain;base64,{b64}" download="newsletter_{nl["sent_at"][:10]}.txt">📥 Download</a>'
st.markdown(link, unsafe_allow_html=True)
with c3:
if st.button("🗑️ Delete", key=f"delete_{nl['id']}"):
st.info("Delete coming soon!")
else:
st.info("📭 No newsletters sent yet. Generate one above!")
with col2:
st.markdown("### Account")
st.write(f"**Logged in as:** {user_email}")
if st.button("🚪 Sign Out"):
sign_out()
st.rerun()
st.markdown("---")
st.subheader("⚙️ Quick Settings")
with st.form("update_name_form"):
new_name = st.text_input("Display Name", value=user_name)
if st.form_submit_button("Update Name"):
if update_user_name(user_email, new_name):
st.success("Name updated!")
st.rerun()
st.markdown("---")
st.write("**Current Preferences:**")
st.write(f"• Industry: {current_industry}")
st.write(f"• Preferred Topic: {current_topic}")
with st.form("update_prefs_form"):
st.write("### Update Preferences")
new_industry = st.selectbox(
"Select your industry",
options=INDUSTRIES,
index=INDUSTRIES.index(current_industry) if current_industry in INDUSTRIES else len(INDUSTRIES) - 1
)
topic_options = list(NEWS_SOURCES.keys())
input_topic = st.text_input(
"Preferred Topic (type or select)",
value=current_topic,
placeholder="Type or select a topic"
)
selected_topic_dropdown = st.selectbox(
"Pick from common topics",
options=topic_options,
index=topic_options.index(current_topic) if current_topic in topic_options else 0
)
use_selected = st.checkbox("Use selected topic above instead of typed?", value=False)
final_topic = selected_topic_dropdown if use_selected else input_topic.strip()
if st.form_submit_button("Update Preferences"):
success = save_preferences(
user_email,
[final_topic] if final_topic else [],
industry=new_industry,
custom_interest=None
)
if success:
st.success("Preferences updated!")
st.rerun()
else:
st.error("Failed to update preferences. Please try again.")
st.markdown("---")
st.markdown(
f'<div style="text-align:center; margin-top:16px;">'
f'<a href="/dashboard" style="color:#667eea; margin:0 24px; text-decoration:underline;">🔄 Change Topic / Preferences</a>'
f'<a href="/unsubscribe?email={user_email}" style="color:#e53935; margin:0 24px; text-decoration:underline;">🚫 Unsubscribe</a>'
'</div>',
unsafe_allow_html=True
)
def main():
if is_authenticated():
show_personal_dashboard()
else:
show_auth_page()
if __name__ == "__main__":
main()
Unsubscribe Flow
unsubscribe_app.py
The Streamlit application lets users unsubscribe from the PaperDrop newsletter. It fetches the user’s email from the query parameters, allows them to confirm the unsubscribe action, and (upon confirmation) calls two functions from your database utility:
save_unsubscribe(email)— records the unsubscribe request for the given email.clear_user_preferences(email)— clears out any user-specific topic/email preferences after an unsubscribe.
Implementation
import streamlit as st
import urllib.parse
from utils.database import save_unsubscribe, clear_user_preferences
st.set_page_config(page_title="Unsubscribe - PaperDrop", page_icon="🚫", layout="centered")
def parse_email_param():
email = st.query_params.get("email", [None])[0]
if email:
return urllib.parse.unquote(email)
return None
def main():
st.title("Unsubscribe from PaperDrop")
email = parse_email_param()
if not email:
st.error("No email address found. Please use a valid unsubscribe link.")
return
unsubscribed = False
if st.button("Confirm Unsubscribe"):
unsubscribed = save_unsubscribe(email)
if unsubscribed:
clear_user_preferences(email)
st.success(f"You have successfully unsubscribed {email}. You won't get future newsletters.")
else:
st.error("Could not process your request. Try again later.")
if unsubscribed:
st.info("You can rejoin anytime by signing up again via the main site.")
if __name__ == "__main__":
main()
How to Run the AI Newsletter App
To run this AI newsletter app, enter this command in your terminal:
streamlit run unsubscribe_app.pyIf you’re building a full stack AI newsletter app, you might have several questions about architecture, tools, and implementation. Below are the most common questions answered in a structured format.
Frequently Asked Questions (FAQs)
An AI-powered newsletter automatically collects content from multiple sources like blogs, research papers, and news sites, then uses large language models (LLMs) to summarize and simplify the information. It delivers personalized insights directly to users via email.
To build an AI newsletter app using Python, you need components for data scraping, AI-based summarization, user authentication, and email delivery. Tools like Streamlit (frontend), Supabase (database), and APIs for LLMs can be combined to create a complete end-to-end system.
AI summarization uses large language models to process long-form content and generate concise, easy-to-understand summaries. These models identify key ideas, remove noise, and present insights in plain language for faster consumption.
AI summarization helps save time, improves information clarity, and enables users to quickly understand complex topics. It is especially useful for staying updated with fast-moving fields like AI, machine learning, and technology.
An AI newsletter system gathers content using web scraping, RSS feeds, and APIs from platforms like news websites, research repositories, and developer communities. The data is then cleaned, filtered, and deduplicated before processing.
Yes, AI newsletters can be personalized based on user preferences such as topics, industry, or interests. The system tailors summaries and insights to match each user’s profile, making the content more relevant and actionable.
Once the content is summarized, it is formatted into a structured HTML email and sent using an email delivery service. These emails typically include summaries, key insights, and links to original sources.
A full-stack AI application typically includes a frontend (like Streamlit or React), a backend database (such as Supabase), APIs for AI models, and integrations for scraping and email delivery. These components work together to automate the entire workflow.
Duplicate content is removed using similarity checks on titles and text. Low-quality or incomplete data is filtered out during the scraping and preprocessing stage to ensure only relevant content is used.
When a user unsubscribes, their email is stored in a separate list and removed from future mailing campaigns. Their preferences may also be cleared to ensure compliance with email regulations.
Yes, the system can be scaled by adding more data sources, improving AI models, and deploying the application on cloud infrastructure. Modular architecture makes it easy to extend features and handle larger user bases.