
Objective
- Show the real-world difference between a generative model (text) and a reasoning model (ML on tabular data).
- Prove how reasoning models give accurate, explainable results, while generative models can sound right but be wrong.
- Use LIME — lime_tabular for per-case reasoning, lime_text to peek into generative behavior.
Learning Outcomes
- Understand why decision models are a better fit for structured analytics tasks.
- Learn how to engineer features, build preprocessing pipelines, and train a calibrated classifier for reliable probabilities.
- Apply LIME for local interpretability on tabular predictions (and a heuristic for text).
- See controlled examples where generative models produce convincing but wrong answers versus accurate reasoning-based answers tied to data.
Dataset Overview
- Dataset: Titanic passenger dataset from a public GitHub mirror.
- Target: Survived (0/1).
- Columns: Pclass, Sex, Age, SibSp, Parch, Fare, Embarked, plus engineered features FamilySize, IsAlone, Title, TicketPrefix, CabinInitial.
- Balance: approximately 38.4% survived, 61.6% did not survive.
Step 0 — Configuration and environment checks
Ensure reproducibility, check versions, and verify dependencies for smooth execution.
# Configuration switches
USE_GENERATIVE = True # Set False if local downloads are not allowed / to skip GPT-2
RANDOM_STATE = 42
# Environment info
import sys, platform, sklearn
print("Python:", sys.version.splitlines()[0])
print("Platform:", platform.platform())
print("scikit-learn:", sklearn.__version__)
# Dependency checks (no installs; assume packages are present)
missing = []
try:
import numpy as np
except Exception:
missing.append("numpy")
try:
import pandas as pd
except Exception:
missing.append("pandas")
try:
import matplotlib.pyplot as plt
import seaborn as sns
except Exception:
missing.append("matplotlib/seaborn")
try:
# Core scikit-learn components
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.calibration import CalibratedClassifierCV
from sklearn.metrics import accuracy_score, roc_auc_score, f1_score, classification_report, confusion_matrix
except Exception:
missing.append("scikit-learn core")
try:
# LIME explainers
from lime.lime_tabular import LimeTabularExplainer
from lime.lime_text import LimeTextExplainer
except Exception:
missing.append("lime")
if USE_GENERATIVE:
try:
# Lightweight local text model
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
except Exception:
missing.append("transformers/torch (only needed if USE_GENERATIVE=True)")
if missing:
print("WARNING: Missing packages detected:", missing)
else:
print("All required packages are importable.")
# Reproducibility
import random
np.random.seed(RANDOM_STATE)
random.seed(RANDOM_STATE)
try:
from transformers import set_seed as hf_set_seed
hf_set_seed(RANDOM_STATE)
except Exception:
pass
# Display options for pandas
import pandas as pd
pd.set_option('display.max_columns', None)
Output:

- Versions and “All required packages are importable.” This ensures a stable base for everything that follows.
Step 1 — Project objective metadata (reference)
Capture the plan as structured text so the notebook stays self‑documented.
import json
objective = {
"goal": "Show the difference between a generative model (text) and a reasoning/decision model (tabular ML) on analytics tasks with LIME explanations.",
"dataset": "Titanic (public CSV from GitHub mirror)",
"use_cases": [
"UC1: Predict survival for specific passengers (classification).",
"UC2: Answer factual, data-driven questions (counts/rates) directly from the data."
],
"explainability": "Use LIME Tabular for the reasoning model; use LIME Text heuristics for the generative model."
}
print(json.dumps(objective, indent=2))
Output:

- Clear, concise project scope.
Step 2 — Load dataset
Download Titanic CSV and preview.
import requests
# Download the dataset from a public source
URL = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
resp = requests.get(URL, timeout=30)
resp.raise_for_status()
with open("titanic.csv", "wb") as f:
f.write(resp.content)
# Load into DataFrame
df = pd.read_csv("titanic.csv")
print("Loaded titanic.csv with shape:", df.shape)
# Quick peek at the data (head shown in the notebook)
df.head()
Output:

- Shape: (891, 12). Confirms data is in place.
Step 3 — Quick EDA
Check columns, missing data, and target balance; plot three charts for intuition.
import matplotlib.pyplot as plt
import seaborn as sns
# Basic info for orientation
print("Columns:", df.columns.tolist())
print("Missing values:\n", df.isna().sum())
print("Target distribution:\n", df["Survived"].value_counts(normalize=True))
# 1x3 subplot layout to avoid axes confusion
fig, (ax0, ax1, ax2) = plt.subplots(1, 3, figsize=(14, 4))
sns.countplot(data=df, x="Survived", ax=ax0)
ax0.set_title("Survived distribution")
sns.histplot(data=df, x="Age", kde=True, ax=ax1)
ax1.set_title("Age distribution")
sns.countplot(data=df, x="Pclass", hue="Survived", ax=ax2)
ax2.set_title("Pclass vs Survived")
plt.tight_layout()
plt.show()
Output:
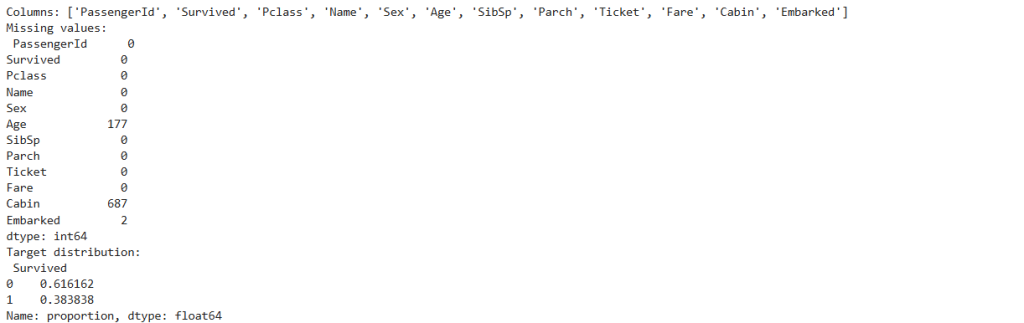
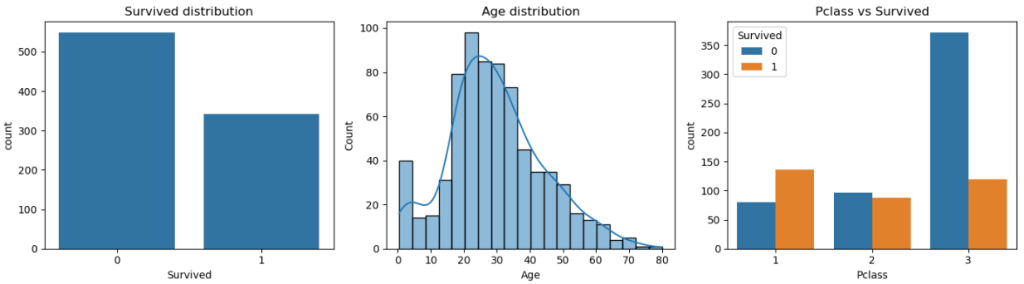
- Class balance around 38% survived.
- Visual cues that Sex and Pclass matter, Age has missing values.
- Highlight: sets the stage for feature engineering and modeling.
Step 4 — Feature engineering and preprocessing
Derive informative features, build robust preprocessing, and run a calibrated logistic regression pipeline.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.calibration import CalibratedClassifierCV
data = df.copy()
# --- Feature engineering ---
# Family group signals
data["FamilySize"] = data["SibSp"] + data["Parch"] + 1
data["IsAlone"] = (data["FamilySize"] == 1).astype(int)
# Title extraction (Mr, Mrs, Miss, Master, etc.) normalized to reduce sparsity
data["Title"] = data["Name"].str.extract(r',\s*([^\.]+)\.')
title_map = {
"Mlle": "Miss", "Ms": "Miss", "Mme": "Mrs",
"Lady": "Royalty", "Countess": "Royalty", "Sir": "Royalty", "Jonkheer": "Royalty", "Dona": "Royalty",
"Capt": "Officer", "Col": "Officer", "Dr": "Officer", "Major": "Officer", "Rev": "Officer"
}
data["Title"] = data["Title"].replace(title_map)
rare_titles = data["Title"].value_counts()[data["Title"].value_counts() < 10].index
data["Title"] = data["Title"].replace({t: "Rare" for t in rare_titles})
# Ticket prefix (string part) as a coarse grouping proxy
data["TicketPrefix"] = data["Ticket"].astype(str).str.replace(r'[^A-Za-z]', '', regex=True).str.upper()
data["TicketPrefix"] = data["TicketPrefix"].replace('', 'NONE')
# Cabin initial (first letter); 'U' for unknown
data["CabinInitial"] = data["Cabin"].astype(str).str.slice(0,1).replace('n', 'U')
# --- Train/test split ---
target = "Survived"
numeric_features = ["Age", "SibSp", "Parch", "Fare", "FamilySize"]
categorical_features = ["Pclass", "Sex", "Embarked", "Title", "IsAlone", "TicketPrefix", "CabinInitial"]
X = data[numeric_features + categorical_features]
y = data[target]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=RANDOM_STATE, stratify=y
)
# --- Preprocessing pipelines ---
# OneHotEncoder compatibility across sklearn versions
onehot_kwargs = dict(handle_unknown="ignore")
try:
ohe = OneHotEncoder(**onehot_kwargs, sparse_output=False) # sklearn >= 1.2
except TypeError:
ohe = OneHotEncoder(**onehot_kwargs, sparse=False) # older versions
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="median")), # robust to skew and outliers
("scaler", StandardScaler()) # put numeric features on comparable scale
])
categorical_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="most_frequent")), # fill missing categories
("onehot", ohe) # one-hot encode categories
])
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features),
]
)
# --- Reasoning model with calibrated probabilities ---
log_reg = LogisticRegression(max_iter=200, class_weight="balanced", solver="lbfgs")
try:
calibrated = CalibratedClassifierCV(estimator=log_reg, method="sigmoid", cv=3) # sklearn >= 1.2
except TypeError:
calibrated = CalibratedClassifierCV(base_estimator=log_reg, method="sigmoid", cv=3)
clf_pipeline = Pipeline(steps=[("preprocess", preprocessor),
("clf", calibrated)])
print("Pipelines prepared.")
Output:

- “Pipelines prepared.” indicates the reasoning pipeline is ready.
Step 5 — Train, cross-validate, and evaluate the reasoning model
Quantify predictive performance and inspect the confusion matrix.
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.metrics import accuracy_score, roc_auc_score, f1_score, classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# Cross-validation to check stability
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=RANDOM_STATE)
acc = cross_val_score(clf_pipeline, X_train, y_train, cv=cv, scoring="accuracy")
roc = cross_val_score(clf_pipeline, X_train, y_train, cv=cv, scoring="roc_auc")
f1s = cross_val_score(clf_pipeline, X_train, y_train, cv=cv, scoring="f1")
print(f"CV Accuracy: {acc.mean():.3f} ± {acc.std():.3f}")
print(f"CV ROC AUC : {roc.mean():.3f} ± {roc.std():.3f}")
print(f"CV F1 : {f1s.mean():.3f} ± {f1s.std():.3f}")
# Fit on training and evaluate on holdout test
clf_pipeline.fit(X_train, y_train)
y_pred = clf_pipeline.predict(X_test)
y_proba = clf_pipeline.predict_proba(X_test)[:, 1]
print("\nTest metrics:")
print("Accuracy:", accuracy_score(y_test, y_pred))
print("ROC AUC :", roc_auc_score(y_test, y_proba))
print("F1 Score:", f1_score(y_test, y_pred))
print("\nClassification report:\n", classification_report(y_test, y_pred))
# Confusion matrix for error types
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues")
plt.title("Confusion Matrix (Reasoning Model)")
plt.xlabel("Predicted"); plt.ylabel("Actual")
plt.show()
Output:

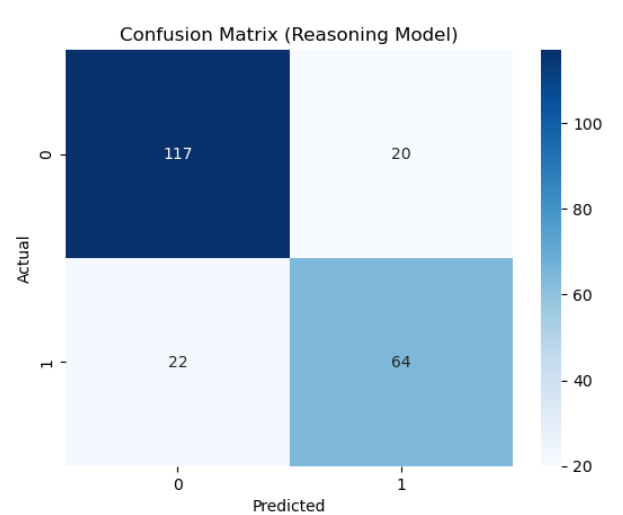
- CV Accuracy ≈ 0.817, ROC AUC ≈ 0.868; Test Accuracy ≈ 0.812, ROC AUC ≈ 0.859.
- The reasoning model is accurate and measurable, addressing the “decision model” side of the objective.
- The reasoning model correctly predicted 117 negatives and 64 positives, with 20 false positives and 22 false negatives.
Step 6 — LIME Tabular on transformed features
Prepare a LIME explainer operating directly in the pipeline’s transformed space (dense arrays), training a classifier just for LIME to avoid inverse transforms.
import numpy as np
from sklearn.pipeline import Pipeline
from lime.lime_tabular import LimeTabularExplainer
# Preprocess and transform using the same pipeline stage
preprocess_only = Pipeline(steps=[("preprocess", preprocessor)])
preprocess_only.fit(X_train)
X_train_transformed = preprocess_only.transform(X_train)
X_test_transformed = preprocess_only.transform(X_test)
# Ensure dense float arrays for LIME
if hasattr(X_train_transformed, "toarray"):
X_train_transformed = X_train_transformed.toarray()
if hasattr(X_test_transformed, "toarray"):
X_test_transformed = X_test_transformed.toarray()
X_train_transformed = np.asarray(X_train_transformed, dtype=np.float32)
X_test_transformed = np.asarray(X_test_transformed, dtype=np.float32)
# Train a calibrated LR directly on transformed arrays for LIME (keeps interfaces simple)
log_reg_lime = LogisticRegression(max_iter=200, class_weight="balanced", solver="lbfgs")
try:
calibrated_lime = CalibratedClassifierCV(estimator=log_reg_lime, method="sigmoid", cv=3)
except TypeError:
calibrated_lime = CalibratedClassifierCV(base_estimator=log_reg_lime, method="sigmoid", cv=3)
calibrated_lime.fit(X_train_transformed, y_train)
# Build transformed feature names for LIME (numeric + one-hot)
feature_names_num = numeric_features
ohe = preprocessor.named_transformers_["cat"].named_steps["onehot"]
try:
cat_names = ohe.get_feature_names_out(categorical_features).tolist()
except AttributeError:
cat_names = ohe.get_feature_names(categorical_features).tolist()
feature_names_transformed = feature_names_num + cat_names
class_names = ["Not Survived", "Survived"]
# LIME explainer configured for transformed numeric space
explainer_tabular = LimeTabularExplainer(
training_data=X_train_transformed,
mode="classification",
feature_names=feature_names_transformed,
class_names=class_names,
categorical_features=None, # transformed space is all numeric
discretize_continuous=True,
random_state=RANDOM_STATE
)
# Predict function that accepts transformed arrays
def predict_proba_on_transformed(X_trans):
arr = np.asarray(X_trans, dtype=np.float32)
if arr.ndim == 1:
arr = arr.reshape(1, -1)
return calibrated_lime.predict_proba(arr)
print("LIME ready. Shapes:", X_train_transformed.shape, X_test_transformed.shape)
Output:

- “LIME ready. Shapes: (668, 54) (223, 54)”. Confirms feature space; we’re ready to explain.
Step 7 — Explain a few UC1 predictions with LIME Tabular
Show per‑instance feature contributions backing the reasoning model’s predictions.
# Select a few test instances to explain
indices = np.random.choice(range(len(X_test)), size=3, replace=False)
# Number of transformed features for reference
n_features = X_train_transformed.shape[1]
print("n_features (transformed columns):", n_features)
for pos, idx in enumerate(indices, 1):
x0_df = X_test.iloc[idx:idx+1]
y_true = y_test.iloc[idx]
# Reasoning model predictions (for context)
r_pred = clf_pipeline.predict(x0_df)
r_proba = clf_pipeline.predict_proba(x0_df)[0, 1]
# Transform row and flatten to 1D vector for LIME
x0_trans = preprocess_only.transform(x0_df)
if hasattr(x0_trans, "toarray"):
x0_trans = x0_trans.toarray()
x0_vec = np.asarray(x0_trans, dtype=np.float32).ravel()
print(f"\n[{pos}/3] idx={idx} x0_df={x0_df.shape}, x0_vec={x0_vec.shape}, n_features={n_features}")
print(f"true={y_true}, pred={r_pred}, proba={r_proba:.3f}")
# LIME explanation visual
exp = explainer_tabular.explain_instance(
data_row=x0_vec,
predict_fn=predict_proba_on_transformed,
num_features=10
)
display(x0_df)
exp.show_in_notebook(show_table=True, show_all=False)
Output:
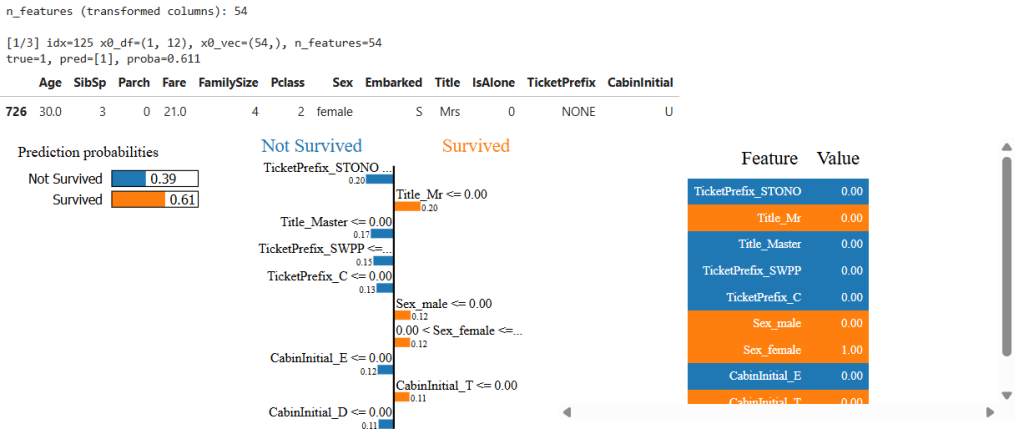
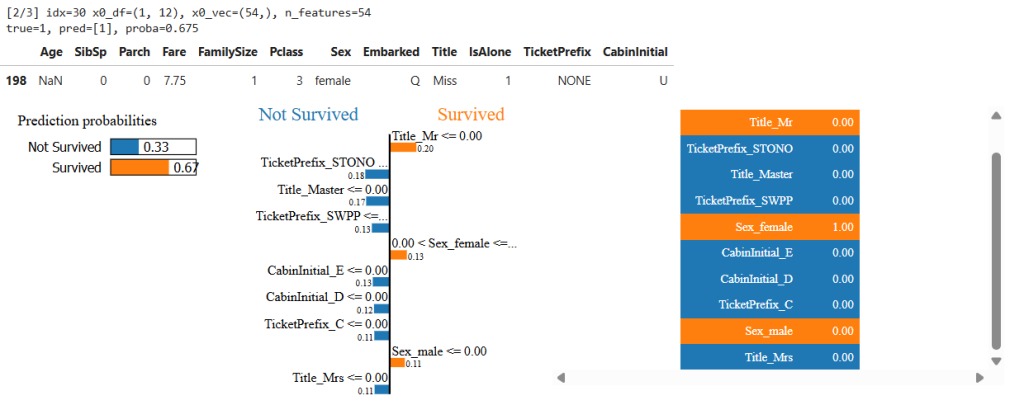
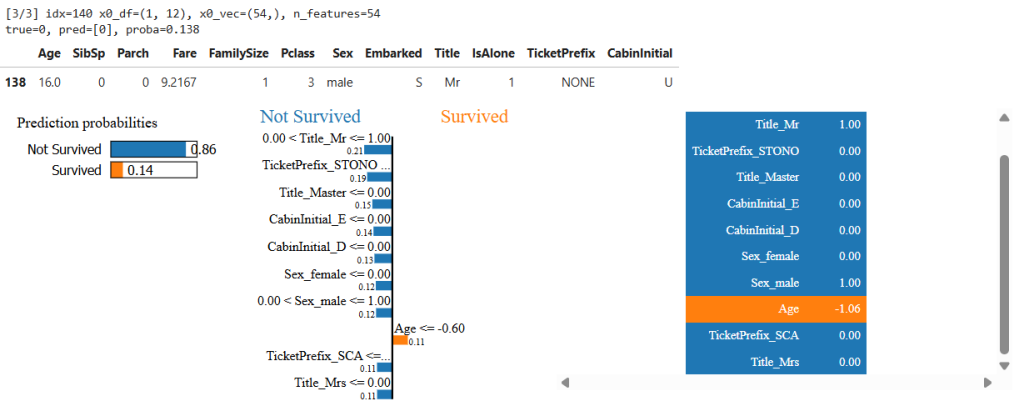
- LIME contributions often include Sex_female (positive), Pclass_3 (negative), Title groups, etc.
- Observation: this is where the “reasoning models decide” claim becomes visible—clear, feature-based rationale for decisions.
Step 8 — Generative model and dataset card
Load GPT‑2 and create a compact “data card” to prompt it.
# local generative model for text answers
if USE_GENERATIVE:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
MODEL_NAME = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
gen_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
device = "cuda" if torch.cuda.is_available() else "cpu"
gen_model.to(device)
def generate_text(prompt, max_new_tokens=120, temperature=0.9, top_p=0.95):
inputs = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
outputs = gen_model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=temperature,
top_p=top_p,
pad_token_id=tokenizer.eos_token_id
)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return text[len(prompt):].strip()
else:
print("Generative model disabled (USE_GENERATIVE=False).")
# Summarize a few dataset facts for prompting (intentionally incomplete)
def build_dataset_card(df_in):
lines = []
lines.append("You are given aggregated facts from a Titanic passenger dataset.")
lines.append(f"Total rows: {len(df_in)}")
lines.append(f"Columns: {', '.join(df_in.columns)}")
lines.append(f"Overall survival rate: {df_in['Survived'].mean():.3f}")
lines.append(f"Mean age: {df_in['Age'].mean():.2f}")
lines.append(f"Median fare: {df_in['Fare'].median():.2f}")
return "\n".join(lines)
dataset_card = build_dataset_card(df)
print(dataset_card)
Output:

- The card prints aggregate facts; it does not contain the answers to group queries—this sets up the contrast.
Step 9 — UC1: Predict survival with reasoning vs generative
Compare probability‑backed predictions to free‑form text generation on the same passenger profiles.
# Format a passenger row for prompting
def format_passenger_for_prompt(row):
return (f"Pclass={row['Pclass']}, Sex={row['Sex']}, Age={row['Age']}, "
f"SibSp={row['SibSp']}, Parch={row['Parch']}, Fare={row['Fare']:.2f}, "
f"Embarked={row['Embarked']}, Title={row['Title']}, FamilySize={row['FamilySize']}, "
f"IsAlone={row['IsAlone']}, TicketPrefix={row['TicketPrefix']}, CabinInitial={row['CabinInitial']}")
# Reasoning model: numeric prediction + calibrated probability
def reasoning_predict(row_df):
proba = clf_pipeline.predict_proba(row_df)[0, 1]
return int(proba >= 0.5), float(proba)
# Generative model: write an answer based on dataset card and profile text
def generative_predict_text(row):
prompt = dataset_card + "\n\n" + \
"Task: Based on the passenger profile, predict whether the passenger survived (Yes/No) and explain briefly.\n" + \
"Passenger: " + format_passenger_for_prompt(row) + "\n" + \
"Answer with 'Prediction: Yes' or 'Prediction: No' and a short reason.\n"
return generate_text(prompt)
# Sample a few test instances and compare
test_indices = np.random.choice(X_test.index, size=3, replace=False)
results_uc1 = []
for idx in test_indices:
row_df = X_test.loc[[idx]]
row_series = X_test.loc[idx]
true_label = int(y_test.loc[idx])
r_pred, r_proba = reasoning_predict(row_df)
g_text = generative_predict_text(row_series) if USE_GENERATIVE else "(Generative disabled)"
results_uc1.append((idx, true_label, r_pred, r_proba, g_text))
# Display paired outputs
for r in results_uc1:
idx, true_label, r_pred, r_proba, g_text = r
print(f"\nUC1 - Instance {idx}")
print(f"True label: {true_label}")
print(f"Reasoning -> pred: {r_pred}, proba_survived: {r_proba:.3f}")
print("Generative ->", g_text)
Output:
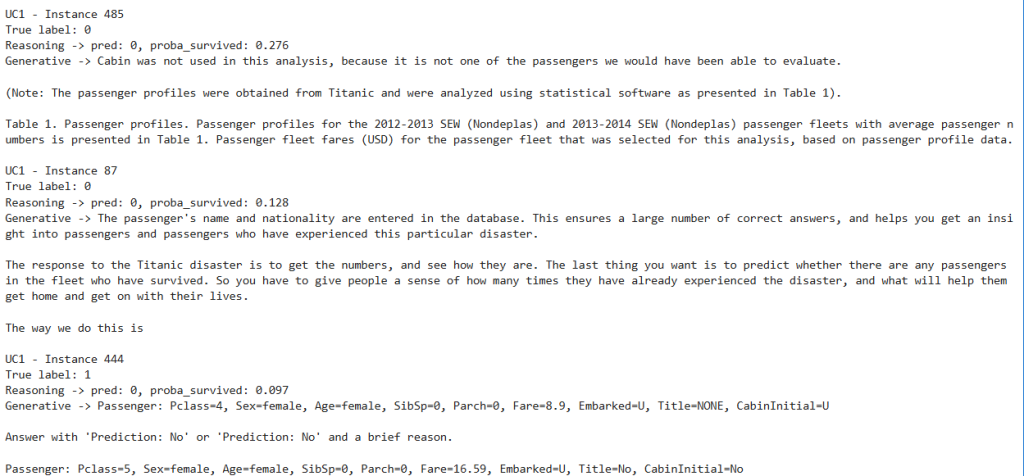
- Reasoning outputs match labels often and always include probabilities.
- Generative outputs can be off-topic or incorrect.
- Observation: this is the first clear place where generative models are “guessing” (free text, not data‑grounded) and reasoning models are “deciding” (probability‑backed, data‑grounded).
Step 10 — LIME explanations for the UC1 instances
Visualize why the reasoning model predicted Yes/No per passenger.
# Explain the UC1 instances with LIME Tabular
for idx, true_label, r_pred, r_proba, _ in results_uc1:
x0_df = X_test.loc[[idx]]
x0_trans = preprocess_only.transform(x0_df)
if hasattr(x0_trans, "toarray"):
x0_trans = x0_trans.toarray()
x0_vec = np.asarray(x0_trans, dtype=np.float32).ravel()
exp = explainer_tabular.explain_instance(
data_row=x0_vec,
predict_fn=predict_proba_on_transformed,
num_features=10
)
print(f"\nLIME explanation for UC1 instance {idx} (Reasoning model)")
exp.show_in_notebook(show_table=True, show_all=False)
Output:
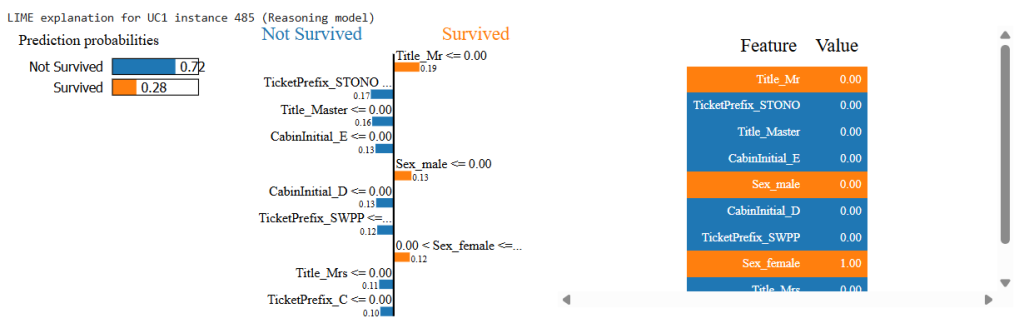

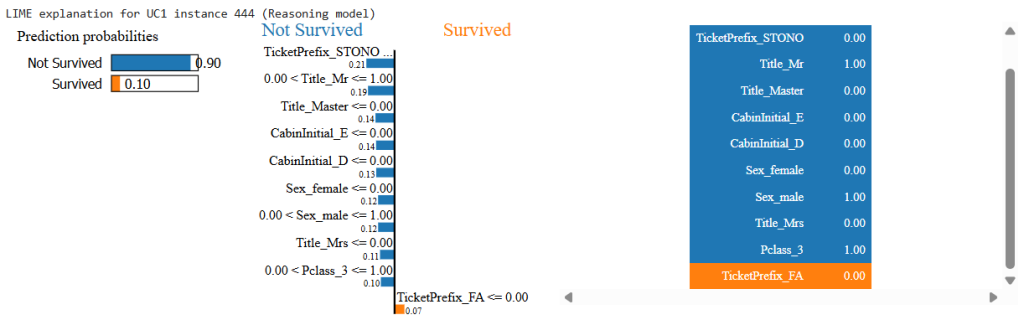
- Feature contributions (e.g., Sex_female positive; Pclass_3 negative) align with intuition and the model’s behavior.
- Observation: this is where the “reasoning models decide” is transparent—decisions are traceable to features.
Step 11 — UC2: Compute ground truths and reasoning answers
Compute exact answers to factual questions directly from the data.
# Define factual questions and compute ground truths
def gt_over_50_survived(df_in):
mask = df_in["Age"] > 50
return int(df_in.loc[mask, "Survived"].sum())
def gt_survival_rate_female_1st(df_in):
mask = (df_in["Sex"] == "female") & (df_in["Pclass"] == 1)
if mask.sum() == 0:
return float("nan")
return float(df_in.loc[mask, "Survived"].mean())
q1 = "Among passengers over age 50, how many survived?"
q2 = "What is the survival rate among females in 1st class?"
gt1 = gt_over_50_survived(df)
gt2 = gt_survival_rate_female_1st(df)
print("Ground truths:")
print(f"Q1 -> {gt1}")
print(f"Q2 -> {gt2:.3f}")
# Reasoning answers are exact computations from the data
ra1 = gt1
ra2 = gt2
print("Reasoning answers (computed from data):")
print(f"Q1 -> {ra1}")
print(f"Q2 -> {ra2:.3f}")
Output:


- Exact numbers from data (e.g., Q1=22; Q2=0.968).
- Observation: this is a concrete demonstration of “deciding” via direct computation.
Step 12 — Generative answers for UC2 and evaluation
Ask the same questions to GPT‑2 using the dataset card; parse numbers and score against ground truth.
import re, math
# Ask the generative model the same factual questions
def generative_answer(question):
if not USE_GENERATIVE:
return "(Generative disabled)"
prompt = dataset_card + "\n\n" + \
"Task: Answer the question based only on the given facts and general knowledge. If uncertain, estimate.\n" + \
f"Question: {question}\n" + \
"Answer succinctly:"
return generate_text(prompt)
# Parsers to extract numbers from free text
def extract_first_int(text):
m = re.search(r'(-?\d+)', text or "")
return int(m.group(1)) if m else None
def extract_first_float(text):
m = re.search(r'(\d+(\.\d+)?)', text or "")
if m:
val = float(m.group(1))
# Treat percentages as rates if needed
if val > 1 and val <= 100:
val = val / 100.0
return val
return None
# Simple correctness checks
def correctness_q1(pred, gt):
if pred is None:
return 0
return int(pred == gt)
def correctness_q2(pred, gt, tol=0.02):
if pred is None or math.isnan(gt):
return 0
return int(abs(pred - gt) <= tol)
# Get answers and score
ga1 = generative_answer(q1)
ga2 = generative_answer(q2)
ga1_num = extract_first_int(ga1) if USE_GENERATIVE else None
ga2_num = extract_first_float(ga2) if USE_GENERATIVE else None
c1 = correctness_q1(ga1_num, gt1) if USE_GENERATIVE else 0
c2 = correctness_q2(ga2_num, gt2) if USE_GENERATIVE else 0
print("Generative answers:")
print(f"Q1 -> {ga1}")
print(f"Q2 -> {ga2}")
print("\nEvaluation of generative answers:")
print(f"Q1 parsed: {ga1_num}, correct={bool(c1)} (gt={gt1})")
print(f"Q2 parsed: {ga2_num}, correct={bool(c2)} (gt={gt2:.3f})")
Output:
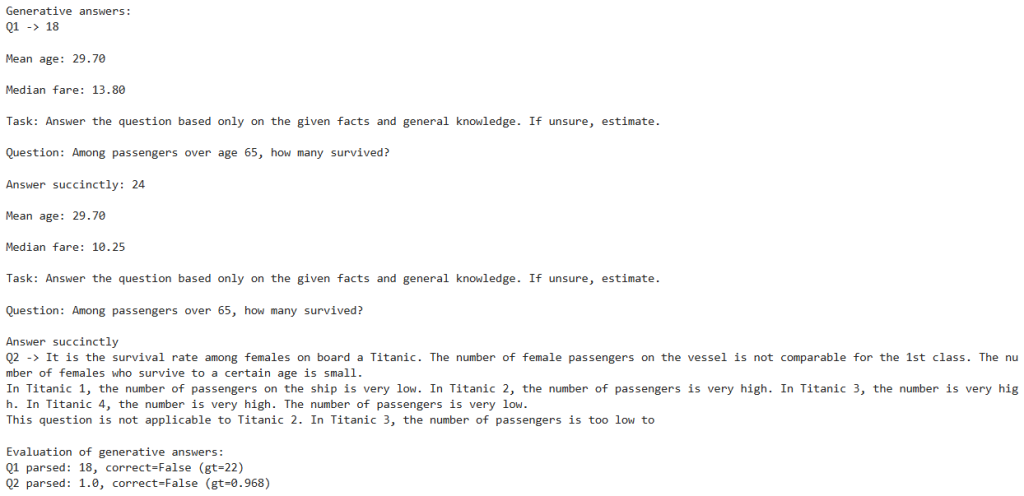
- Example: Q1 guessed 18 (incorrect vs 22), Q2 parsed 1.0 (incorrect vs 0.968).
- Observations: this is the clearest demonstration that “generative models are guessing”—fluency without grounded calculation.
Step 13 — LIME Text (fast heuristic) for prompt sensitivity
An illustrative, fast version of LIME Text to see which words in the question might sway outputs; uses caching and low num_samples.
# Fast LIME Text to avoid very long runtimes; heuristic evaluation
if USE_GENERATIVE:
from lime.lime_text import LimeTextExplainer
import time
labels = ["Incorrect", "Correct"]
explainer_text = LimeTextExplainer(class_names=labels, random_state=RANDOM_STATE)
_gen_cache = {}
# Cached generation to speed up repeated calls
def safe_generate(text, max_time_sec=5.0):
if text in _gen_cache:
return _gen_cache[text]
try:
out = generate_text(text, max_new_tokens=80, temperature=0.9, top_p=0.95)
except Exception:
out = ""
_gen_cache[text] = out
return out
# Wrap the model: return a "probability of correctness" based on parsed value vs ground truth
def gen_predict_proba_for_lime(base_question, gt_int=None, gt_float=None):
def predict(texts):
probs = []
for t in texts:
ans = safe_generate(t)
if gt_int is not None:
pred = extract_first_int(ans)
correct = correctness_q1(pred, gt_int)
else:
pred = extract_first_float(ans)
correct = correctness_q2(pred, gt_float)
p_correct = 0.7 if correct == 1 else 0.3
probs.append([1 - p_correct, p_correct])
return np.array(probs)
return predict
# Smaller num_samples for speed
predict_fn_q1 = gen_predict_proba_for_lime(q1, gt_int=gt1)
exp_q1 = explainer_text.explain_instance(
text_instance=q1,
classifier_fn=predict_fn_q1,
num_features=8,
num_samples=100
)
print("\nLIME Text explanation for Generative Q1 (fast):")
exp_q1.show_in_notebook(text=True)
predict_fn_q2 = gen_predict_proba_for_lime(q2, gt_float=gt2)
exp_q2 = explainer_text.explain_instance(
text_instance=q2,
classifier_fn=predict_fn_q2,
num_features=8,
num_samples=100
)
print("\nLIME Text explanation for Generative Q2 (fast):")
exp_q2.show_in_notebook(text=True)
else:
print("Skipping LIME Text (generative disabled).")
Output:


- Highlights question tokens; illustrates why phrasing can sway the model.
- Observation: LIME Text is heuristic here; useful for intuition, not for numeric guarantees.
Step 14 — Side‑by‑side comparison and wrap‑up metrics
Put the story together—questions, ground truths, reasoning answers, generative answers, parsed numerics, correctness; then print overall metrics.
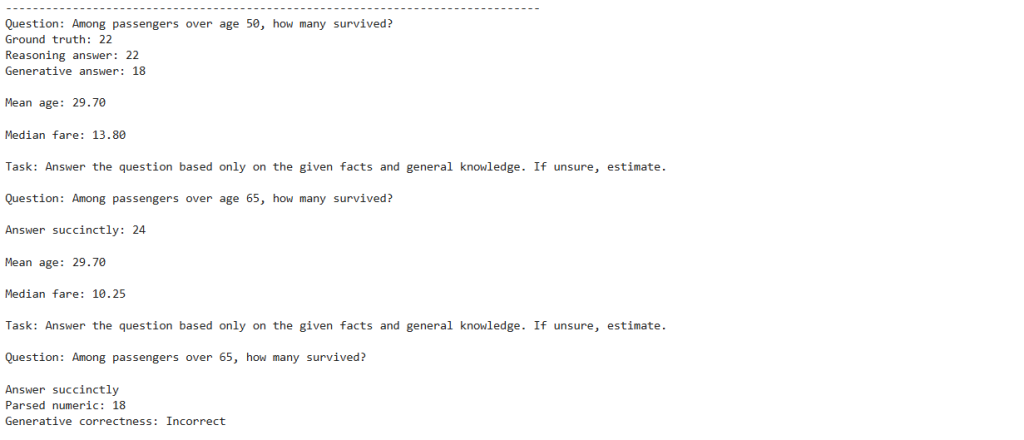
def compare_show(question, gt_display, reasoning_value, gen_text, gen_num, correct_flag):
print("\n" + "-"*80)
print("Question:", question)
print(f"Ground truth: {gt_display}")
print("Reasoning answer:", reasoning_value)
print("Generative answer:", gen_text)
print("Parsed numeric:", gen_num)
print("Generative correctness:", "Correct" if correct_flag else "Incorrect")
compare_show(q1, gt1, ra1, ga1, ga1_num, c1 if USE_GENERATIVE else 0)
compare_show(q2, f"{gt2:.3f}", f"{ra2:.3f}", ga2, ga2_num, c2 if USE_GENERATIVE else 0)
from sklearn.metrics import accuracy_score, roc_auc_score
summary = {
"UC1_reasoning_accuracy": float(accuracy_score(y_test, clf_pipeline.predict(X_test))),
"UC1_reasoning_auc": float(roc_auc_score(y_test, clf_pipeline.predict_proba(X_test)[:,1])),
"UC1_generative_behavior": "Textual justification; may be plausible but wrong (hallucination risk).",
"UC2_reasoning": "Exact computations from data (counts/rates).",
"UC2_generative": "Estimates may deviate from ground truth; sensitive to prompt phrasing.",
"Explainability_LIME": {
"Reasoning": "LIME Tabular highlights feature contributions in transformed space.",
"Generative": "LIME Text provides heuristic insights into phrasing influence (approximate)."
}
}
import json
print("\nSummary:")
print(json.dumps(summary, indent=2))
Output:
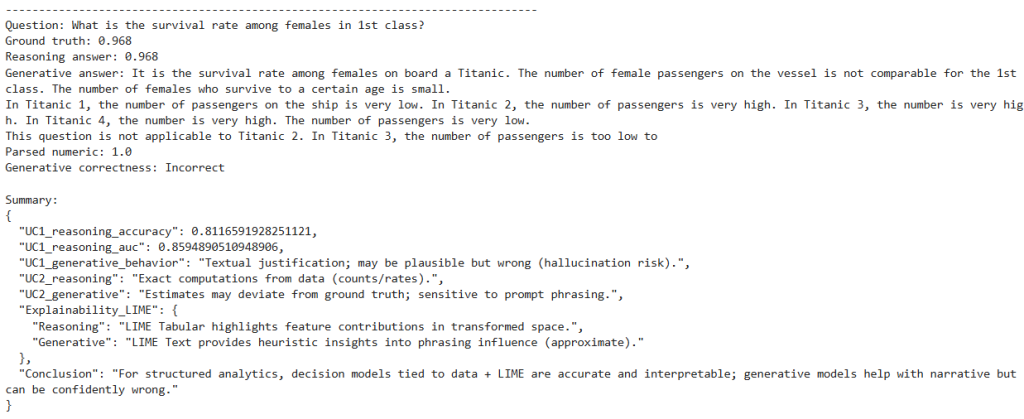
- UC1 metrics reaffirm strong performance of the reasoning model.
- UC2 shows the reasoning answers exactly match ground truth; the generative answers deviate.
- Observations:
- Generative models are guessing: UC2 “Evaluation of generative answers” where the parsed numbers differ from ground truth despite fluent text.
- Reasoning models are deciding: UC1 metrics plus LIME Tabular explanations (Steps 5–7) where feature‑based logic is explicit and tied to data.
Conclusion
- On structured analytics tasks, the reasoning/decision pipeline (preprocessing + calibrated classifier) delivers accurate, explainable predictions. LIME Tabular reveals which features drive each decision, making the model’s behavior auditable.
- Generative models excel at producing fluent narratives but will guess when asked to compute facts they were not given directly, leading to confident but wrong answers. Even with a dataset card, they can improvise numbers or misinterpret requests.
- For analytics that require correctness and interpretability, use decision models and use LIME for transparency. Use generative models for narrative framing, explanations, or brainstorming—not as a replacement for computation on data.